
Suppose we have a machine learning model, 𝑓, that predicts the price of an insurance bonus, Y, for data that includes a sensitive attribute, such as gender. Discrimination may occur due to statistical bias (past injustices or sample imbalance), a correlation between the sensitive attribute and some explanatory variable, or intentional bias .
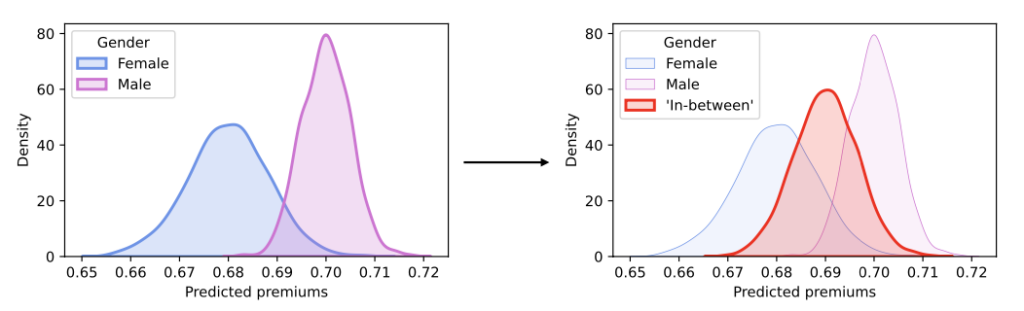
To avoid this bias, there has been legislation (such as the AI ACT - Europe, 2024) that limits or even eliminates the use of certain sensitive attributes in artificial intelligence models. However, simply removing these attributes is not always the solution that generates the best level of fairness or the best model performance. There are preprocessing approaches (which modify the input data), processing approaches (which add a fairness penalty), and postprocessing approaches (which modify the univariate distribution of predictions to create an intermediate distribution, as done in Sequential Fairness)
There have been several postprocessing approaches to mitigate these effects if a model has a single sensitive attribute (Single sensitive atribute, SSA). But what can we do if there are multiple sensitive attributes (Multiple sensitive atribute, MSA)? One possible approach is to consider the intersection of the distributions created by each of the combinations of the sensitive attributes. For example, if the sensitive attributes are gender (female and male) and ethnicity (black and white), these four cases would be considered with the SSA approach:

This can be computationally expensive as the number of sensitive attributes increases. Additionally, when adding a new sensitive attribute, the previous work is lost because new distributions must be found with the new combinations. Another approach (which is the focus of this blog) is Sequential Fairness. In summary, this approach seeks to modify the model's predictions to be fair for the first sensitive attribute and then modify these new predictions again to be fair for the second attribute (and consequently also for the first), and so on. The benefits of this approach are that it is a commutative process (the order of the sequence of attributes to make the model fair does not matter), it is easy to add new sensitive attributes, and it also makes interpretability easier.
The idea is to find a representative distribution that lies between the conditional distributions for the predictions of the sensitive attributes. This is achieved using the Wasserstein barycenter, which tries to minimize the total cost of moving one distribution to another through optimal transport. The concept of the Wasserstein barycenter extends the idea ofStrong Demographic Parity) to multiple attributes, which seeks to reduce inequity in groups and requires that a model's predictions be independent of sensitive attributes.
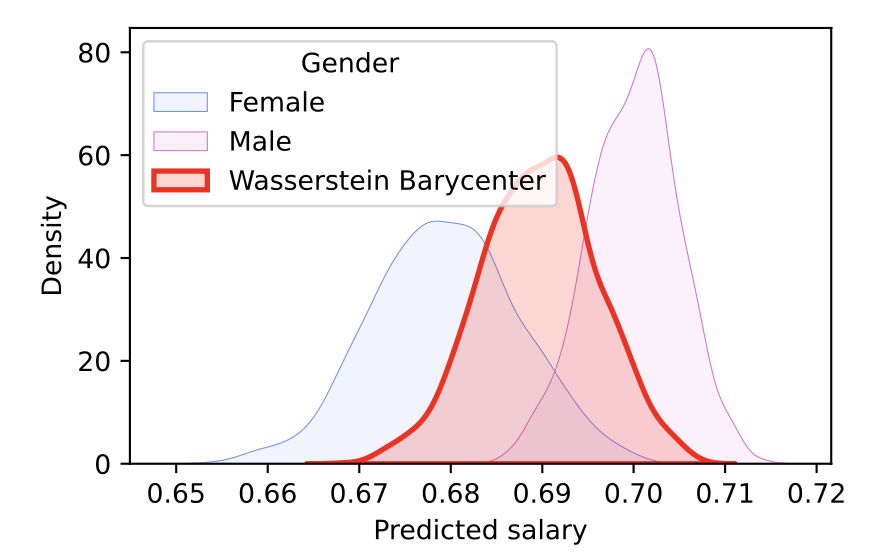
It is important to note that methods for reducing unfairness in predictive models always come at a cost to performance. However, this approach, by using the Wasserstein barycenter, ensures that metrics like accuracy and MSE suffer the least possible damage.
Equipy is a Python package that implement Sequential Fairness in continuous prediction models with multiple sensitive attributes, using the concept of the Wasserstein barycenter to minimize the impact on model performance while mitigating bias and discrimination that may arise from sensitive attributes in predictions.
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.