
Asesor: Juan Fernando Pérez Bernal
Los asentamientos informales son definidos como áreas residenciales cuyos habitantes no poseen tenencia legal de las tierras, los barrios carecen de servicios básicos e infraestructura urbana y no cumplen con requisitos de planificación, así como se pueden encontrar en zonas de peligro ambiental y geográfico (ONU, 2015). El auge de este tipo de asentamientos suele ser resultado de la urbanización acelerada de las últimas décadas en muchas ciudades del mundo, generando desafíos significativos para la planificación urbana, pues es necesario que haya una adaptación y gestión del desarrollo de manera eficaz para evitar problemas como la congestión, la falta de infraestructura adecuada y la degradación del medio ambiente.
Así pues, la identificación y localización de este tipo de asentamientos resulta ser un problema relevante para contar con una mejor planificación urbana de la ciudad, pues permitiría plantear políticas para gestionar el desarrollo de estos espacios de una mejor manera. En este trabajo se explora el uso de redes neuronales en grafos (GNN, por sus siglas en inglés), particularmente redes neuronales convolucionales sobre grafos (GCN) para clasificar barrios como «legalizados» o «informales» y estimar el porcentaje de áreas informales en las Unidades de Planeación Zonal (UPZ) en la ciudad de Bogotá D.C, Colombia.
En principio, para clasificar adecuadamente las áreas informales en Bogotá es necesario contar con datos sobre la tenencia legal de la tierra, sin embargo, la falta de estos datos representó un obstáculo importante para el desarrollo de este proyecto. Actualmente, la ciudad cuenta con bases de datos públicas como Datos Abiertos Bogotá (D.A.B) o la Infraestructura de Datos Espaciales para el Distrito Capital (IDECA) que proveen información acerca de las etiquetas sobre algunos barrios; es decir, si son “legalizados” o “informales”, pero esta información no se encuentra con uniformidad o concordancia con reportes oficiales de formalidad.
Con lo anterior en mente, la metodología del proyecto consta de 2 modelos, ambos basados en la aplicación de redes neuronales sobre grafos (GNN) para procesar datos espaciales, satelitales, geográficos y de salud con el fin de clasificar asentamientos informales en Bogotá. El primero de ellos con el objetivo de poder solventar el problema de uniformidad o concordancia de las etiquetas de “legalizado” o “informal”, mientras que, el segundo de ellos se enfoca en la estimación del porcentaje de las áreas informales.
Este primer modelo fue elaborado empleando GCN para clasificar los barrios de Bogotá según su estatus de legalización, de modo que fuera posible solventar los problemas de uniformidad que presentan las fuentes con esta información. Para ello, fue necesario construir el grafo utilizado por el modelo, el cual corresponde a un grafo de la ciudad de Bogotá a partir de la información disponible del Laboratorio Urbano de Bogotá (IDECA, 2016) y la plataforma Datos Abiertos Bogotá (Secretaría Distrital de Planeación, 2024) en el que los vértices corresponden a cada uno de los barrios de la ciudad mientras que las aristas corresponden a las conexiones entre ellos según la proximidad geográfica.
Luego, se empleó la base de datos de la Secretaría Distrital de Planeación que proporciona información sobre los asentamientos informales de la ciudad que, históricamente, han completado con éxito el proceso de legalización. Los barrios que incluyen estos asentamientos se clasifican como “informales” ya que, a pesar de haber sido formalizados, aún conservan características similares a los asentamientos que no han sido identificados. Por el otro lado, se utilizó la información de los barrios “legalizados” del IDECA. Finalmente, los barrios que no han sido contemplados se van a clasifican como “desconocidos” y son los que un modelo inicial se va a encargar de clasificar. La Figura 1 muestra la distribución de los barrios y sus respectivas etiquetas.
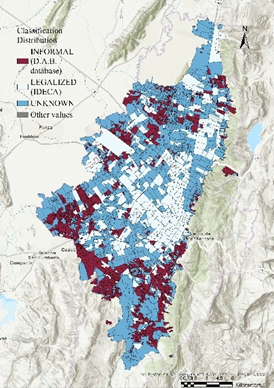
Figure 1. Clasificación inicial de los barrios de Bogotá, Colombia, año 2016.
Con el grafo, las etiquetas y un conjunto de atributos (correspondiente a los atributos de cada nodo) construido a partir de datos satelitales del año 2016 que incluyen información de imágenes nocturnas (luminiscencia) y características de edificaciones (altura promedio, cantidad de edificios y porcentaje de área construida), se entrenó el modelo (basado en el artículo de Kumagai, Iwata y Fujiwara (2020)) únicamente con los barrios conocidos (legalizados e informales) y se propagó las etiquetas a barrios sin clasificar.
Para medir la efectividad de la clasificación, se calculó el Área Bajo la Curva (AUC) de la función ROC, obteniendo un valor de 88.89% destacando así la capacidad del modelo para diferenciar entre barrios formales e informales. Por último, se visualizaron los resultados del modelo sobre un mapa de la ciudad de Bogotá, como se puede observar en la Figura 2.
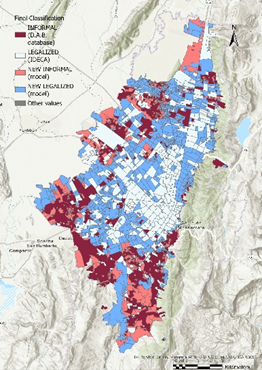
Figure 2. Clasificación de los barrios de Bogotá, Colombia según el modelo de clasificación, año 2016.
Una vez solventado el problema de la variable a predecir, se continuo con el modelo que estimar el porcentaje de áreas informales a nivel de UPZ. Para ello, se calcula en primera instancia la variable a estimar a partir de las etiquetas propagadas en la fase anterior, lo que en otras palabras corresponde a la proporción de área informal dentro de cada UPZ.
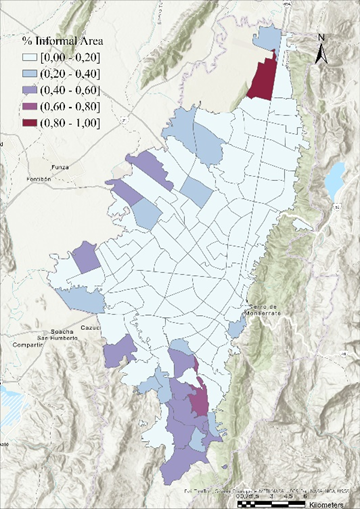
Figure 3. Porcentaje de área informal por UPZ, año 2016.
Además de la variable a estimar, se consideraron fuentes de información como la encuesta multipropósito del Departamento Administrativo Nacional de Estadística (DANE) y registros de llamadas a la línea de emergencias 123 seleccionando variables que se usaron como atributos para el modelo, encontrando las más significativas mediante la correlación de Spearman. Entre estas variables se encuentran el nivel educativo del jefe de hogar, el tamaño promedio del hogar, las tasas de intoxicación anuales, entre otros.
El modelo de predicción empleado incluye capas convolucionales en grafos para agregar información de nodos vecinos y bloques de redes neuronales feedforward para mejorar el ajuste. Además, se aplicaron técnicas de regularización, como el dropout, para prevenir el sobreajuste. Como resultado notable del modelo se tiene que este alcanzó un MAE de 7.06%, además logró predecir el 80% de los valores de UPZ (ver Figura 3) con un error inferior al 10%. Sin embargo, se observaron dificultades para predecir áreas con altos niveles de informalidad, debido en parte a la escasez de datos disponibles y la acumulación del error del modelo anterior. En la Figura 4, se muestra el resultado final de la estimación realizada por el modelo a nivel de UPZ.
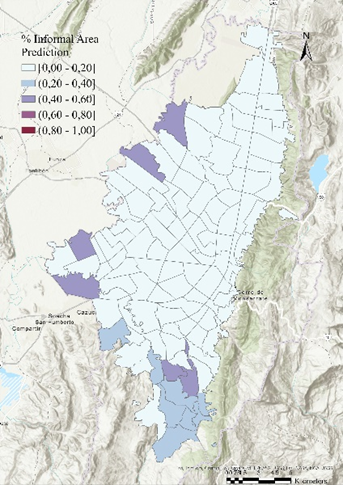
Figure 4. Predicciones de informalidad a nivel UPZ del modelo, año 2017
Conclusiones
A pesar de las limitaciones, los resultados resaltan el potencial de las GNN para complementar información faltante en instancias dependientes entre sí. Este enfoque se presenta como una alternativa prometedora para abordar problemas de planificación urbana, como la identificación y gestión de asentamientos informales en las ciudades.
Es importante subrayar que la formalización de asentamientos no solo brinda acceso a servicios básicos, sino que también mejora la calidad de vida de sus habitantes. Por lo tanto, debe ser una prioridad para las entidades gubernamentales en sus planificaciones urbanas.
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
Link to the seminar presentation
https://www.youtube.com/live/umaiIJXvN3o?si=7G2ZH9VfWj2Q-cR3
References
Atsutoshi Kumagai, Tomoharu Iwata, and Yasuhiro Fujiwara. «Semi-supervised Anomaly Detection on Attributed Graphs”. In: (Feb. 2020).
Infraestructura de datos espaciales de Bogotá -IDECA. Barrios de Bogotá 2016. Oct. 2017. URL:https://bogota-laburbano.opendatasoft.com/explore/dataset/barrios_prueba/information/ .
ONU-HÁBITAT III. “22- Asentamientos Informales”.In: Naciones Unidas (2015), p. 10. URL: http://habitat3.org/wp-content/uploads/Issue-Paper-22_ASENTAMIENTOS-INFORMALES-SP.pdf
Secretaría Distrital de Planeación. Barrio legalizado. Bogotá D.C. May 2024. URL: https://datosabiertos.bogota.gov.co/dataset/barrio-legalizado-bogota-d-c.
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.