
¿Cómo podríamos estimar el número de desaparecidos por el conflicto armado colombiano? O ¿Cuántos individuos quedan de una población de animales en vía de extinción? Estas son preguntas que permiten responder los estimadores de captura y recaptura, en últimas, estos buscan calcular la cantidad total de la población existente con base en información recopilada a través de muestras.
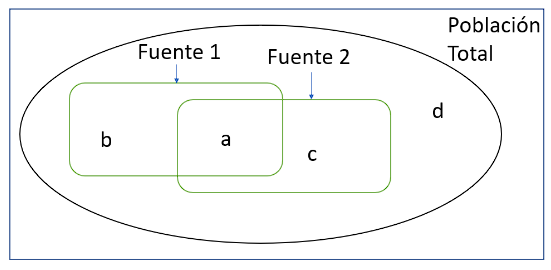
La figura 1 presenta el método de captura y recaptura. En este, suponga que tiene una población total sobre la que desconoce su tamaño (N) representada por la letra d, pero, a través del muestreo identificó a dos partes de la población (fuente 1 y 2). Ahora, sea b el número de individuos en la fuente 1, c el número de individuos en la fuente 2 and a el número de individuos que aparecen en ambas fuentes. Entonces se puede estimar la cantidad total de individuos (N) como N= c*b/a. No obstante, para que esta estimación sea posible se debe partir de un supuesto importante: independencia entre listas. Este supuesto sugiere que la probabilidad de ser capturado en una lista es independiente de la probabilidad de ser capturada en otra.
Figura 1: representación gráfica del método de captura y recaptura con dos fuentes
Claro, este supuesto es plausible en poblaciones de animales, donde la probabilidad de capturar un individuo es independiente de recapturarlo. No obstante, en poblaciones sociales como las personas pueden haber patrones de comportamiento como la ubicación, las migraciones, entre otros que hagan que un individuo sea capturado en múltiples listas, violando el cumplimiento de este supuesto. Aunque, en épocas modernas se desarrollaron nuevas formas de estimación más elaboradas como los modelos log-lineales, no obstante, siguen partiendo de este “dudoso” supuesto o relajándolo a que esta probabilidad es independiente si “condiciono” por algunas características observables.
En esta línea, Mateo Dulce ofrece una solución muy inteligente. Utiliza una reciente literatura sobre estimadores robustos para encontrar una forma estadística, con mínima varianza, insesgada y consistente de estimar este parámetro, incluso si se rompe este supuesto de independencia. Para esto, intuitivamente trata de estimar el sesgo presente en la estimación inicial, usando teoría de eficiencia semiparamétrica. Dada la dificultad que tiene explicar estos de forma intuitiva, les dejo los enlaces de la página de Mateo Dulce por si quieren aprender más sobre el tema:
También, pueden seguir el canal de youtube de Quantil, donde se publican las grabaciones de los semilleros. Entre estos el de Mateo.
Quantil Matemáticas Aplicadas – YouTube
Muchas gracias por leerme.
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.