
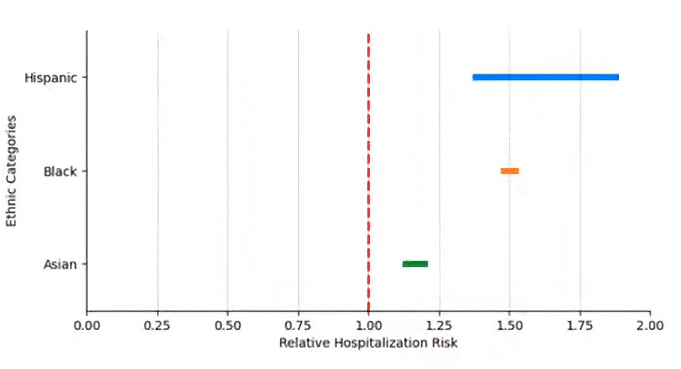
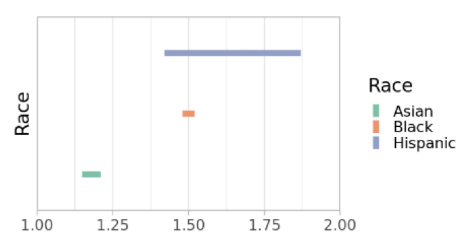
Figure 2. Estimation of f(P) by Racial Group in COVID-19 Hospitalization
Even when bias in the estimates is minimized, uncertainty remains a key challenge. Most current methods for uncertainty quantification produce confidence intervals without taking into account the context in which decisions will be made based on them. In many applications, it is not enough to guarantee that the prediction contains the true value with a certain probability; the prediction sets must also be consistent with the decision-making structure.
Let us consider the example of medical diagnosis in dermatology, as discussed in the article by Cortes-Gomez et al. (2024). A standard conformal prediction method might generate a set of possible diagnoses with a high probability of including the true condition. However, this set could be clinically difficult to interpret if it includes diseases spanning multiple distinct categories—some benign and others malignant. As mentioned in the presentation, different labels within the prediction set imply completely different diagnostic and treatment actions.
To address this limitation, a decision-focused uncertainty quantification approach has been developed. This adapts the conformal prediction framework to minimize a decision loss 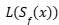 associated with the prediction set
associated with the prediction set 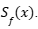 The objective is to minimize the
The objective is to minimize the 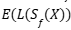 expected loss subject to the
expected loss subject to the 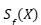 constraint that Y the prediction set covers
constraint that Y the prediction set covers 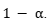 . For the case in which the loss function is separable, the problem has a closed-form solution using a Neyman-Pearson–type decision rule, based on the ratio between the conditional probability and the penalty of including each label. In the general case, it is solved through a combinatorial optimization over the prediction set, followed by a conformal adjustment to ensure statistical coverage.
. For the case in which the loss function is separable, the problem has a closed-form solution using a Neyman-Pearson–type decision rule, based on the ratio between the conditional probability and the penalty of including each label. In the general case, it is solved through a combinatorial optimization over the prediction set, followed by a conformal adjustment to ensure statistical coverage.