
In recent years, artificial intelligence models have demonstrated incredible potential to transform industries, from healthcare to finance. However, they have also revealed a troubling issue: algorithmic bias. This phenomenon occurs when AI models reflect and amplify prejudices present in the data they were trained on, which can lead to unfair or discriminatory decisions.
Regulations in various countries have sought to impose restrictions to mitigate the discriminatory effects that the use of artificial intelligence models could have. However, Emily Black, Assistant Professor of Computer Science and Data Science at NYU, points out in her research Algorithmic Fairness and Vertical Equity: Income Fairness in Tax Audits that the regulatory approach based on legal constraints can create tensions with previously successful mitigation strategies. In this regard, Emily addresses three important topics:
EN-ES-EN Traductor dijo: The risk of bias in artificial intelligence models is not a recent phenomenon. For many years, efforts have been made to prevent biases through constraints in the training of machine learning models. Just as models are designed to be accurate, it is also possible to restrict their structure to ensure fairness.
Regulation in the United States, specifically related to discrimination, is outlined in The Fair Housing Act (access to housing), Title VII of the Civil Rights Act (access to employment), and The Equal Credit Opportunity Act (access to credit). This regulation is divided into two parts. The first is Disparate Treatment which prohibits intentional discrimination. This means that using demographic information to make decisions in the three mentioned areas—housing, employment, and credit—is illegal. The second part is Disparate Impact , which states that even if it is unclear whether the model is engaging in discrimination, it may still be illegal to have a system involved in decision-making processes that produces differential impacts across demographic groups.
This is where the first tension arises: how is it possible to mitigate the impact that exists between different demographic groups if it is not legal to consider demographic groups when making decisions?
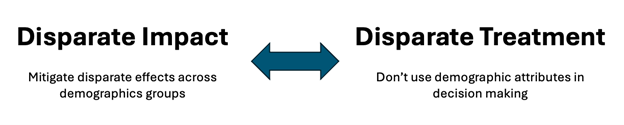
Figure 1. Tension between regulatory definitions in the U.S. Taken and adapted from Emily Black’s seminar (March, 2025)
This tension becomes even deeper with the use of artificial intelligence systems, because the interpretation of the law prohibits the explicit use of demographic information as a model parameter, as well as its inclusion as a constraint during training. Similarly, these restrictions also apply to data that may be highly correlated with demographic characteristics, such as an individual’s place of residence. However, academic literature suggests that the most effective strategy for mitigating bias involves imposing constraints on models using demographic information—yet the law prohibits it. So, how is it possible to pursue solutions against discrimination?
EN-ES-EN Traductor dijo: Emily suggests that the mitigation strategy must go beyond abstracting input and output data; attention must be paid to all algorithm design decisions being made. This includes how the problem is formulated, the collection and preprocessing of data, and the type of model to be used. This is known as the Pipeline Aware Approach to AI Fairness (an approach to fairness through the design of the pipeline).
Change in design decisions: IRS – selection of tax audits
This practical example is based on data from the United States Internal Revenue Service (IRS). The project aimed to improve the selection of individuals for tax audits by using more advanced artificial intelligence models than the linear models the IRS had been using for years. The challenge was not only to improve the model’s accuracy but also to address the unfairness in audit selection, which disproportionately affected low-income individuals.
The IRS provided two main datasets for this study:
When analyzing the data, Emily and her team discovered that low-income individuals were audited more frequently, while middle- and high-income individuals were audited less often. However, upon examining the tax fraud data, they found that higher-income individuals had a greater likelihood of committing fraud, indicating that the current system was unfair.
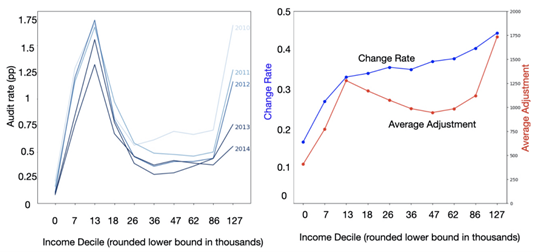
Figure 2. On the left, audit rate by income decile. On the right, the rate of tax underreporting as a percentage of the population. Taken from [1].
Improving the model without demographic constraints
The first attempt at improvement consisted of replacing the linear model with a more complex one, such as a Random Forest, without changing the problem formulation. However, this did not solve the issue of discrimination, as the model continued to primarily select middle- and low-income individuals for audits, while ignoring high-income taxpayers.
The next step was to apply traditional AI fairness methods, such as imposing constraints on the model to ensure that all income deciles had the same likelihood of being selected for an audit. Although this approach slightly improved fairness, it also significantly reduced the amount of money recovered by the IRS and increased the false positive rate.
Changes in algorithm design
The most effective solution emerged from changing the problem formulation. Instead of predicting whether a person would commit fraud (a classification problem), the team decided to predict how much money would be at stake in the event of fraud (a regression problem). This change in the algorithm's design allowed the model to prioritize higher-income individuals, who were more likely to commit significant fraud, while also reducing discrimination against low-income individuals.
With this approach, Emily incorporated the principle of vertical equity, in which she proposed that taxpayers with greater economic capacity (vertical equity) should be treated differently—being audited with higher priority due to the potentially greater impact of their actions on tax revenue. At the same time, it avoids placing a disproportionate burden on low-income taxpayers, contributing to a fairer and more equitable system.
This approach not only improved the fairness of the model but also increased the amount of money recovered by the IRS—from $3 billion to over $10 billion. Although there was an increase in the false positive rate, the IRS considered that the financial benefit justified this trade-off.
Predictive multiplicity and its relationship with fairness
Emily also introduced the concept of “predictive multiplicity,” a phenomenon in which multiple models with the same predictive accuracy can make different predictions for the same individuals. This phenomenon is especially relevant in complex models, such as deep learning models, where variance is higher. While multiplicity might seem problematic, it also offers an opportunity to select models that are not only accurate but also fairer.
In the legal context, Emily argued that companies cannot justify discrimination in their models by claiming it is necessary to maintain accuracy. If there are other models with the same predictive performance but less discrimination, companies are obligated to use those models. This approach reinforces the idea that fairness must be a key consideration in the design of artificial intelligence algorithms.
Conclusión
Emily Black’s work highlights the importance of addressing discrimination in artificial intelligence models through changes in algorithm design, rather than relying solely on training constraints. By reformulating the problem and considering predictive multiplicity, it is possible to create models that are not only accurate but also fairer. This approach has not only practical implications—as in the case of the IRS—but also legal ones, reinforcing the need for companies to prioritize fairness in their AI systems.
In summary, fairness in artificial intelligence is not just a matter of tweaking parameters, but of rethinking how models are designed and selected to ensure they are both equitable and effective.
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
References
[1] Emily Black, Hadi Elzayn, Alexandra Chouldechova, Jacob Goldin, and Daniel Ho. (2022). Algorithmic Fairness and Vertical Equity: Income Fairness with IRS Tax Audit Models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22). Association for Computing Machinery, New York, NY, USA, 1479–1503. https://doi.org/10.1145/3531146.3533204
[2] Emily Black, Manish Raghavan, and Solon Barocas. (2022). Model Multiplicity: Opportunities, Concerns, and Solutions. In 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22), June 21–24, 2022, Seoul, Republic of Korea. ACM, New York, NY, USA, 23 pages. https://doi.org/10.1145/3531146.3533149
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.