
 According to the National Indigenous Organization of Colombia (ONIC), there are 69 languages spoken in Colombia, 65 of which are indigenous languages. This makes Colombia the third most linguistically diverse country in Latin America, after Brazil and Mexico., with a notable concentration in the Amazon and Vaupés areas.. In addition to dialectal diversity, there is an important morphological richness, because in Colombia the four classic morphological types are represented: flexional (Kogui, Arhuaco), agglutinating (Achagua, Andoque, Páez), isolating (Embera, Criollo de San Andrés) and polysynthetic (Kamsá).
According to the National Indigenous Organization of Colombia (ONIC), there are 69 languages spoken in Colombia, 65 of which are indigenous languages. This makes Colombia the third most linguistically diverse country in Latin America, after Brazil and Mexico., with a notable concentration in the Amazon and Vaupés areas.. In addition to dialectal diversity, there is an important morphological richness, because in Colombia the four classic morphological types are represented: flexional (Kogui, Arhuaco), agglutinating (Achagua, Andoque, Páez), isolating (Embera, Criollo de San Andrés) and polysynthetic (Kamsá).
According to the United Nations, at least 43% of the approximately 6,000 languages spoken on the planet are in danger of extinction.. This situation is also reflected in Colombia, where many indigenous languages are at risk due to the small number of native speakers. The preservation of these languages, which contain ancestral cultures, histories and knowledge, is further complicated by the preference of some communities for oral tradition over written tradition. A clear example is the Inga community, where it is thought that abandoning oral practices would lead to the loss of other traditions that require interaction and dialogue between people that foster spaces for discussion and community cohesion..
In 2023, students and professors from the Universidad de Los Andes presented a proposal to preserve the indigenous languages of Colombia. The project sought to consolidate translation datasets of some Colombian languages, which would later be used to build translation models from Spanish into indigenous languages. Previously, there had been little research on indigenous languages in Colombia, with only two previous studies found. One of these studies focused on Wayuunaiki, consolidating an extensive dataset of translated word and phrase pairs between the two languages. The other study covered both Wayuunaiki and Nasa, and showed significant progress in consolidating translation models. For the final study, the Wayuunaiki and Ika languages, two of the most widely spoken indigenous languages in the territory, were taken into account.
Wayuunaiki is an indigenous language spoken mainly in the region of La Guajira, in northern Colombia, and in parts of Venezuela. It is an agglutinative language, meaning that words are formed by joining independent monemes. In 2018, the census determined that the Wayuu population exceeded 380,000, consolidating it as the largest indigenous community in Colombia. On the other hand, Ika is the language spoken by the Arhuaca community, which has more than 34,000 inhabitants and is mainly found in the departments of Magdalena, La Guajira and Cesar, with its epicenter in the western and southeastern part of the Sierra Nevada de Santa Marta. This language belongs to the Chibcha family and is characterized by forming sentences by adding several morphemes to a root or lexeme.
The consolidation of the datasets for Wayuunaiki and Ika began with the search for information, followed by the processing of the sources found. For Wayuunaiki, four sources were used: the bible, the constitution, a story translated from Wayuu to Spanish and a dictionary built by one of the previous researches on translation of indigenous languages, which represented the source with the highest number of sentences of the whole project. For Ika, four sources were again found: the bible, the constitution, a story, and a series of stories and poems. For both languages the data had to be processed in different ways, using tools such as web scraping and OCR (optical character recognition) followed by a manual review to consolidate the datasets.
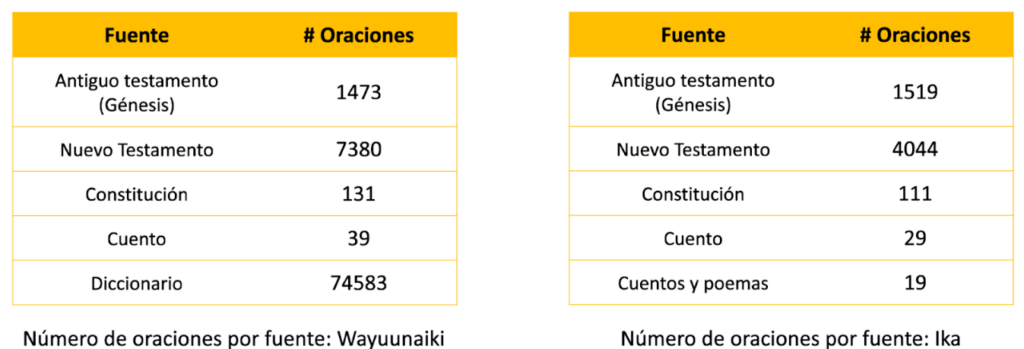
Figure 1: Number of sentences by information source
Building a translation model with a low-resource language is a difficult task. Current translators for languages such as Spanish, English and French have been trained with hundreds of millions of translated sentences and billions of tokens. However, this is not possible for low-resource languages, which are characterized by the lack of annotated text, conversational data and, in general, the absence of the necessary resources to train effective language models.
Even so, the existence of large language models (LLMs) allows a different strategy than training a translation model from scratch: it is possible to use a pre-trained model in high-resource languages and fit it to the data of a low-resource language using the little data available. This approach was applied in two of the three strategies employed by Melissa Robles, Cristian Martínez, Juan Camilo Prieto, Sara Palacios and Rubén Manrique. The first strategy used a Finnish to Spanish translation model. The second used a multilingual model developed by Meta called No Language Left Behind (NLLB). The third consisted of training translation models from scratch, using only the data collected from the two indigenous languages.
The first strategy was based on a previously trained model with Spanish and Finnish sentence pairs from the MarianMT family of models. Finnish, like many indigenous languages, is an agglutinative language, where words are formed by joining independent morphemes. The second model, NLLB, was trained on 200 different languages, including several low-resource languages. To avoid overfitting of these, the team that developed NLLB implemented special techniques such as the regularización, el curriculum learning y el back translation. The last strategy consisted of training a transformer-based translation model without any prior training, using the data set that obtained the best results in the two previous strategies.
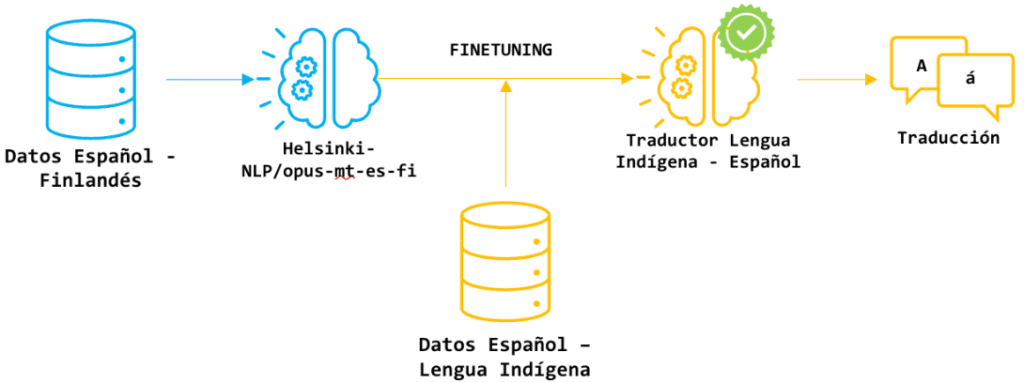
Figure 2: Pre-trained model fitting process
The BLEU and ChrF++ metrics, commonly used in translation tasks, were used to measure the results. The results showed that strategies based on previously trained models outperformed the trained model by more than twice in both metrics only with the indigenous language data, highlighting the importance of using prior information for training. Among the first two strategies, the second one, which employs the multilingual model, obtained the best results, reaching a BLEU above 12 points and a ChrF++ above 35 for Wayuunaiki, and more than 6 and 30, respectively, for Ika, using the best data combinations. For Wayuunaiki, these results are more than double those obtained in previous studies.
Among the two base models used, the one that obtained better results was the NLLB, probably due to its size and the inclusion of low-resource languages in its training. In addition, the importance of the quantity and quality of the data is highlighted, evidenced in the difference in metrics between Wayuunaiki and Ika, probably attributed to the disproportion of digital resources between the two languages. Therefore, it is considered that the main efforts to improve the models for these and other languages should focus on the collection and digitization of data, with the aim of creating more robust and updated models that help communities preserve their traditions and mother tongues.
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.