

Cuerpo (responder a las preguntas que se puedan hacer los usuarios durante la lectura: )
Buscamos reducir los estándares de Copia de los evaluados implementando técnicas de análisis estadístico usando una medida de concordancia entre dos variables, por ejemplo, para evaluar la reproducibilidad o la confiabilidad entre los evaluados. Con esto en mente, fortalecemos las habilidades de detección para mejorar los resultados en general y ofrecer evaluados más capacitados para ingresar a una educación superior o profesores que puedan enseñar más eficientemente. Además de mejorar las posibilidades para que los estudiantes con más capacidades puedan ingresar a la educación superior de forma gratuita o con un cobro mínimo.
En la primera etapa se construyó un índice para detección de posibles casos de copia en exámenes de selección múltiple (para lo cual se usaron dos pruebas: Saber 11 y Docentes). El esquema tomó como base de construcción el índice kappa, usado ampliamente en la literatura por autores tales como Sotaridona & Meijer, Angoff y Belleza & Belleza; la contribución principal fue el uso de una técnica de recodificación de las respuestas que facilitaba el cálculo masivo del índice. En esencia, para cada pareja de sujetos que presenta al tiempo un examen en un mismo salón, distinguiendo un individuo como la fuente y el otro como el sujeto de evaluación de copia, se calcula la probabilidad de presentar conjuntamente las respuestas observadas, suponiendo una distribución invariante a través de preguntas.
Los resultados fueron prometedores y planteaban oportunidades de mejora, que fueron enfrentados en la segunda etapa; particularmente, se extendió a la posibilidad de cambiar la distribución conjunta de posibles respuestas según la pregunta en el examen, y se robusteció el tratamiento de los individuos, modelando las diferencias de habilidades de los mismos. El índice construido en esta etapa fue basado en el índice omega, también descrito en la literatura, y mejoraba el error Tipo I (es decir, el error de acusar de copia a inocentes) frente al índice kappa, manteniendo un error Tipo II similar (es decir, el error de no detectar culpables de copia).
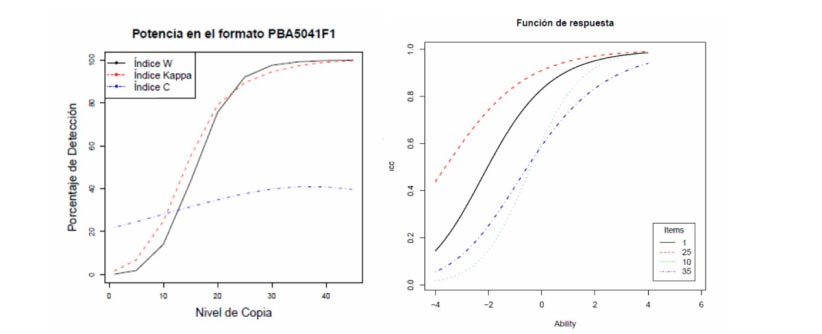
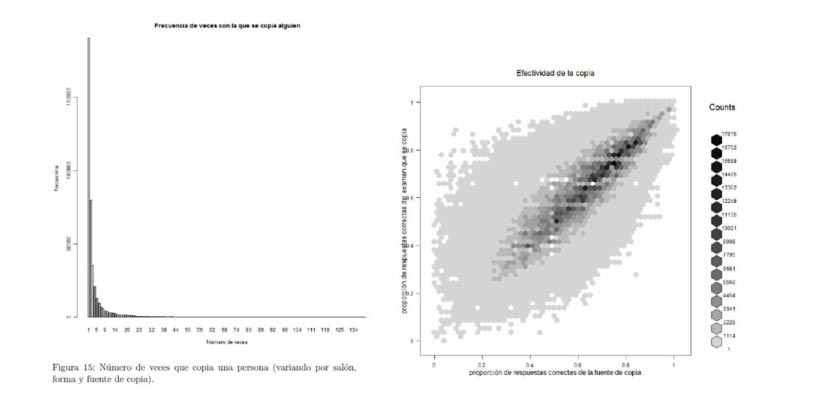
Varias funcionalidades fueron aplicadas con el índice, tales como el cálculo de proporción de individuos sospechosos de copia, de parejas ordenadas sospechosas de copia, de salones donde se sospecha pudo haberse presentado copia, y de sede-jornadas donde se sospecha se presentó copia masiva.
Estos modelos fueron implementados en el ICFES. Posteriormente, el trabajo fue publicado por tres quantileros en el Journal of Educational and Behavioral Statistics en agosto de 2015, con el título “On the Optimality of Answer-Copying Indices: Theory and Practice.”
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.