
Podemos ver el mundo como un ‘ambiente’, en donde para cada período del tiempo un agente se encuentra en un estado y toma una acción de las disponible en ese estado; dependiendo de la configuración del ambiente, el agente recibe una recompensa y llega a un siguiente estado. A su vez, decimos que una política es un vector de probabilidades, tal que para cada estado, este vector determina la probabilidad de tomar cada una de las acciones disponibles. Un ambiente configurado junto con una política dada es lo que formalmente se conoce en la literatura de RL como un Proceso de Recompensa de Markov (MRP).
El objetivo va a ser establecer cuánto es el valor de seguir esa política dada, a partir de una trayectoria de observaciones dependientes (esto se enmarca en un MRP). Puede darse el caso que estas observaciones se generen con la misma política que se busca evaluar o que se generan con una política distinta; en el primer caso estaremos en un escenario on-policy mientras que en el segundo nos referimos a un escenario off-policy (Ramprasad et al, 2022).
Saber el valor de una política nos permite comparar diferentes políticas y elegir una sobre la otra. Un ejemplo sencillo para ver esto es el caso de las cuarentenas, bienestar social y el COVID; poner cuarentenas permitiría controlar más el contagio, pero a su vez aumenta los niveles de pobreza en la medida que la capacidad de generar ingresos de las personas se ve reducida. Suponga que usted es un gobernante y debe decidir para cada uno de los 365 días del año, si ese día pone o no cuarentena, así una política podría ser poner cuarentena solo los días pares, otra política podría ser poner cuarentenas cada 3 meses, etc. Estas hacen parte del abanico de políticas que puede implementar, usted quiere compararlas y con base en ello decide cual implementar.
Ahora, encontrar la función valor de una política no es algo trivial; en el mejor de los casos, se conoce toda la información del ambiente y se puede acceder fácilmente a él, cuando esto ocurre, la ecuación de Bellman permite encontrar la función valor sin mayor esfuerzo (Sutton & Barto, 2018). Sin embargo, es común que en RL exista incertidumbre o que el ambiente sea muy grande, y que por tanto no podamos usar esta ecuación.
En estos casos, RL puede usar alternativas, una de ellas es la Aproximación Lineal Estocástica (LSA). Este es un algoritmo iterativo que permite encontrar soluciones de ecuaciones lineales partiendo de datos observados con incertidumbres (Haskell, 2018). En el marco general, el error de LSA es una diferencia de martingalas, en palabras sencillas, es relajar el supuesto de independencia y que el error tenga “media cero” para que el algoritmo de LSA converja. El problema es que cuando se aplica LSA a RL, usando una aproximación lineal de la función valor, este supuesto se incumple y el ruido se vuelve Markoviano, haciendo referencia a que ahora el ruido depende de un proceso estocástico discreto tal que la probabilidad de ocurrencia de un evento depende del evento inmediatamente anterior.
Aún así, Liang (2010) muestra que teóricamente es posible escribir el ruido Markoviano como un ruido de martingalas y otra parte de ruidos residuales decrecientes. Aunque esto permite seguir aplicando LSA; en la práctica, no es posible obtener estos valores por separado, por eso los resultados estarán sesgados. Entre los métodos clásicos de LSA que se aplican a RL están Diferencias Temporales (TD) para el caso on-policy, mientras que para el caso off-policy son los métodos de Gradiente de Diferencias Temporales (GTD). Estos métodos, aunque tienen un desempeño bastante aceptable, se pueden mejorar si se trata de corregir el sesgo mencionado anteriormente.
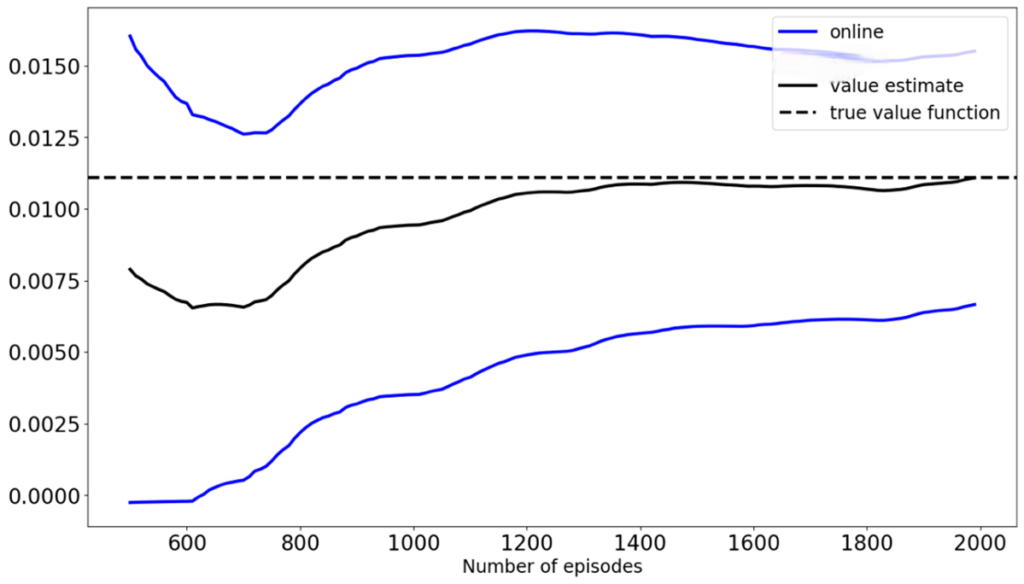
Gráfica 1: TD vs el Online Bootstrap.
Precisamente para realizar esta mejora, Ramprasad et al (2022) proponen el método de Online Bootstrap Inference. Este consiste en agregarle a los métodos clásicos, un bootstrap estadístico, en donde para cada período de tiempo se realizan B iteraciones penalizadas del parámetro de LSA y a partir de este, se construyen unos intervalos de confianza para la función valor. La gráfica 1 muestra una comparación entre TD y el Online Bootstrap para ambiente de Frozen Lake de OpenAI gym, y una política épsilon-greedy con e=0.2. Esta se construye con el código propuesto por Ramprasad et al (2022). Los resultados muestran que TD (línea negra) aproxima de manera cercana el valor real de la función valor (línea punteada) aunque tiene un descache hasta las 2000 iteraciones, mientras que el Online Bootstrap (líneas azules) garantiza que la función valor verdadera estará dentro del intervalo de confianza a partir de las 600 iteraciones. Por otro lado, encontramos que a medida que aumenta la aleatoriedad de la política a evaluar, la convergencia del algoritmo de online Bootstrap se ralentizaba y la amplitud de los intervalos de confianza aumentaba significativamente.
Referencias:
Haskell, W. B. (2018). Introduction to dynamic programming. Na- tional University of Singapore. ISE 6509: Theory and Algorithms for Dynamic Programming.
Liang, F. (2010). Trajectory averaging for stochastic approximation mcmc algorithms. The Annals of Statistics.Vol. 38, No. 5 (October 2010), pp. 2823- 2856.
Ramprasad, P., Li, Y., Yang, Z., Wang, Z., Sun, W., and Cheng, G. (2022). Online bootrstrap inference for policy evaluation in reinfor- cement learning. Journal of the American Statistical Association, pp. 1-14.
Sutton, R. and Barto, A. (2018). Reinforcement learning: An introduction. The MIT Press.
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.