
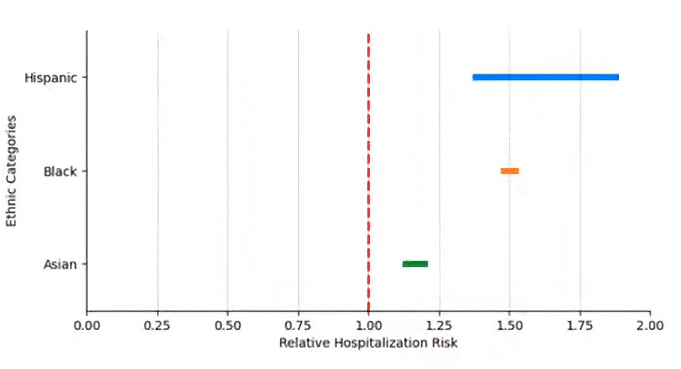
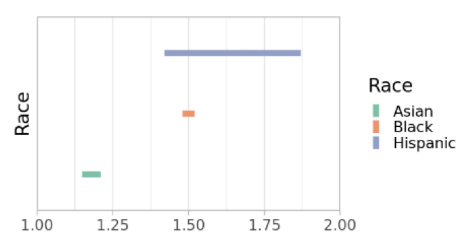
Figura 2. Estimación de f(P) por Grupo Racial en Hospitalización COVID-19
Aun cuando se logra minimizar el sesgo en las estimaciones, la incertidumbre sigue siendo un desafío clave. La mayoría de los métodos actuales de cuantificación de incertidumbre producen intervalos de confianza sin considerar el contexto en el que se tomarán decisiones basadas en ellos. En muchas aplicaciones, no basta con garantizar que la predicción contenga el valor verdadero con cierta probabilidad, sino que los conjuntos de predicción sean coherentes con la estructura de decisión.
Consideremos el ejemplo del diagnóstico médico en dermatología, como se discute en el artículo de Cortes-Gomez et al. (2024). Un método estándar de predicción conformal podría generar un conjunto de posibles diagnósticos con una alta probabilidad de incluir la enfermedad real. Sin embargo, este conjunto podría ser difícil de interpretar clínicamente si incluye enfermedades que abarcan múltiples categorías distintas, algunas benignas y otras malignas. Como se mencionó en la presentación, diferentes etiquetas dentro del conjunto de predicción implican acciones de diagnóstico y tratamiento completamente distintas.
Para abordar esta limitación, se ha desarrollado un enfoque de cuantificación de incertidumbre enfocado en decisiones. Este adapta el marco de predicción conformal para minimizar una pérdida de decisión 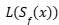 asociada al conjunto de predicción
asociada al conjunto de predicción 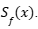 Se plantea la minimización de
Se plantea la minimización de 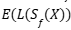 bajo la restricción de que
bajo la restricción de que 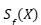 cubra la verdadera etiqueta Y con probabilidad al menos
cubra la verdadera etiqueta Y con probabilidad al menos 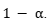 Para el caso en que la función de pérdida es separable, el problema tiene solución cerrada mediante una regla de decisión tipo Neyman-Pearson basada en la razón entre la probabilidad condicional y la penalización de incluir cada etiqueta. En el caso general, se resuelve mediante una optimización combinatoria sobre el conjunto de predicción, seguido de un ajuste conformal para garantizar cobertura estadística.
Para el caso en que la función de pérdida es separable, el problema tiene solución cerrada mediante una regla de decisión tipo Neyman-Pearson basada en la razón entre la probabilidad condicional y la penalización de incluir cada etiqueta. En el caso general, se resuelve mediante una optimización combinatoria sobre el conjunto de predicción, seguido de un ajuste conformal para garantizar cobertura estadística.