
En los últimos años, los modelos de inteligencia artificial han demostrado un potencial increíble para transformar industrias, desde la salud hasta las finanzas. Sin embargo, también han expuesto un problema preocupante: el sesgo algorítmico. Este fenómeno ocurre cuando los modelos de inteligencia artificial reflejan y amplifican prejuicios presentes en los datos con los que fueron entrenados, lo que puede llevar a decisiones injustas o discriminatorias.
La regulación de distintos países ha buscado imponer restricciones para mitigar los efectos discriminatorios que podría tener el uso de modelos de inteligencia artificial. No obstante, Emily Black, profesora asistente de Ciencias de la Computación y Ciencia de Datos de NYU señala en su investigación Algorithmic Fairness and Vertical Equity: Income Fairness in Tax Audits que el enfoque regulatorio basado en restricciones legales puede generar tensiones con estrategias de mitigación previamente exitosas.En este sentido, Emily aborda tres temas importantes:
El riesgo de sesgos en los modelos de inteligencia artificial no es un fenómeno reciente. Desde hace muchos años se ha procurado evitar los sesgos por medio de restricciones en el entrenamiento de los modelos de aprendizaje de máquinas. Así como se busca que los modelos sean precisos, también es posible restringir su estructura para que sean justos.
La regulación en Estados Unidos, específicamente relacionada con discriminación, está contenida en The Fair Housing Act (acceso a vivienda), Title VII of the Civil Rights Act (acceso a empleo) y The Equal Credit Opportunity Act (acceso a crédito). Esta regulación se divide en dos partes. La primera es el Disparate Treatment que prohíbe la discriminación intencional. Esto significa que el uso de información demográfica para tomar decisiones en las tres aplicaciones mencionadas (vivienda, empleo y crédito) es ilegal. La segunda parte es el Disparate Impact el cual indica que aun cuando no se sabe si el modelo está incurriendo en discriminación, puede ser ilegal tener un sistema que interviene en los procesos de toma de decisiones y que tenga un impacto diferencial entre los grupos demográficos.
Aquí es donde aparece la primera tensión: ¿cómo es posible mitigar el impacto que existe entre diferentes grupos demográficos si no es legal pensar en grupos demográficos cuando se toman las decisiones?
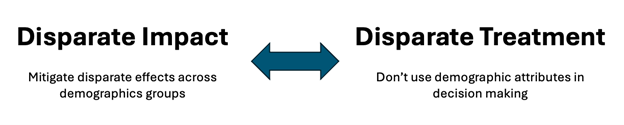
Figura 1. Tensión entre las definiciones regulatorias en EEUU. Tomado y adaptado del seminario de Emily Black (Marzo, 2025)
Esta tensión se hace más profunda en el uso de los sistemas con inteligencia artificial, porque la interpretación de la ley prohíbe el uso explícito de información demográfica como parámetro del modelo, y su inclusión como restricción durante el entrenamiento. De igual forma, estas restricciones aplican para datos que puedan presentar una alta correlación con características demográficas como el lugar de residencia de los individuos. Sin embargo, la literatura académica sugiere que la mejor estrategia para mitigar los sesgos está relacionada con imponer restricciones a los modelos por medio de información demográfica, pero la ley lo impide. Entonces ¿cómo es posible abordar las soluciones en contra de la discriminación?
Emily sugiere que la estrategia de mitigación debe ir más allá de la abstracción de los datos de entrada y salida; se debe prestar atención a todas las decisiones de diseño de los algoritmos que se están tomando. Desde cómo se formula el problema, pasando por la recolección y preprocesamiento de los datos hasta qué tipo de modelo se usará. Esto se denomina Pipeline Aware Approach to AI Fairness (enfoque de justicia a través del diseño del pipeline).
Cambio en las decisiones de diseño: IRS – selección de auditorías fiscales
Este ejemplo práctico está basado en datos del Servicio de Impuestos Internos (IRS) de los Estados Unidos. El proyecto tenía como objetivo mejorar la selección de personas para auditorías fiscales utilizando modelos de inteligencia artificial más avanzados que los modelos lineales que el IRS había estado utilizando durante años. El desafío no solo era mejorar la precisión del modelo, sino también abordar la injusticia en la selección de auditorías, que afectaba desproporcionadamente a las personas de bajos ingresos.
El IRS proporcionó dos conjuntos de datos principales para este estudio:
Al analizar los datos, Emily y su equipo descubrieron que las personas con ingresos más bajos eran auditadas con mayor frecuencia, mientras que las personas con ingresos medios y altos eran auditadas con menor frecuencia. Sin embargo, al examinar los datos de fraude fiscal, encontraron que las personas con ingresos más altos tenían una mayor probabilidad de cometer fraude, lo que indicaba que el sistema actual era injusto.
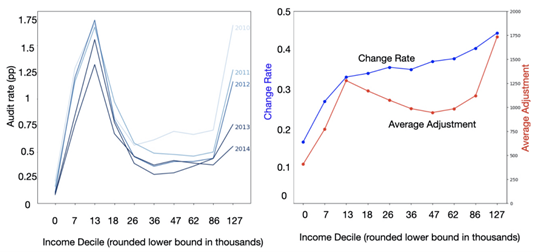
Figura 2. A la izquierda, tasa de auditorías por decil de ingresos. A la derecha, la tasa de omisión de reportes de impuestos como porcentaje de la población. Tomado de [1].
Mejoras el modelo sin restricciones demográficas
El primer intento de mejora consistió en reemplazar el modelo lineal con un modelo más complejo, como un Random Forest, sin cambiar la formulación del problema. Sin embargo, esto no resolvió el problema de discriminación, ya que el modelo continuó seleccionando principalmente a personas de ingresos medios y bajos para las auditorías, ignorando a los contribuyentes de altos ingresos.
El siguiente paso fue aplicar métodos tradicionales de justicia en inteligencia artificial , como imponer restricciones en el modelo para garantizar que todos los deciles de ingresos tuvieran la misma probabilidad de ser seleccionados para una auditoría. Aunque este enfoque mejoró ligeramente la justicia, también redujo significativamente la cantidad de dinero recuperado por el IRS y aumentó la tasa de falsos positivos.
Cambios en el diseño del algoritmo
La solución más efectiva surgió al cambiar la formulación del problema. En lugar de predecir si una persona cometería fraude (un problema de clasificación), el equipo decidió predecir cuánto dinero estaría en juego en caso de fraude (un problema de regresión). Este cambio en el diseño del algoritmo permitió que el modelo priorizara a las personas con mayores ingresos, que tenían más probabilidades de cometer fraudes significativos, y al mismo tiempo redujo la discriminación hacia las personas de bajos ingresos.
Con este enfoque, Emily incorporó el principio de equidad vertical (vertical equity), en el que propuso que los contribuyentes con mayor capacidad económica (ingresos más altos) sean tratados de manera diferenciada, al ser auditados con mayor prioridad debido al impacto potencialmente mayor de sus acciones en los ingresos fiscales. Al mismo tiempo, se evita imponer una carga desproporcionada sobre los contribuyentes de bajos ingresos, lo que contribuye a un sistema más justo y equitativo.
Este enfoque no solo mejoró la justicia del modelo, sino que también aumentó la cantidad de dinero recuperado por el IRS, de $3 mil millones a más de $10 mil millones. Aunque hubo un aumento en la tasa de falsos positivos, el IRS consideró que el beneficio financiero justificaba este sacrificio.
Multiplicidad predictiva y su relación con la justicia
Emily también introdujo el concepto de “multiplicidad predictiva”, un fenómeno en el que varios modelos con la misma capacidad predictiva pueden hacer predicciones diferentes para los mismos individuos. Este fenómeno es especialmente relevante en modelos complejos, como los de aprendizaje profundo, donde la varianza es mayor. Aunque la multiplicidad puede parecer problemática, también ofrece una oportunidad para seleccionar modelos que no solo sean precisos, sino también más justos.
En el contexto legal, Emily argumentó que las empresas no pueden justificar la discriminación en sus modelos afirmando que es necesaria para mantener la precisión. Si existen otros modelos con la misma capacidad predictiva pero menos discriminación, las empresas están obligadas a utilizar esos modelos. Este enfoque refuerza la idea de que la justicia debe ser una consideración clave en el diseño de algoritmos de inteligencia artificial.
Conclusión
El trabajo de Emily Black destaca la importancia de abordar la discriminación en los modelos de inteligencia artificial a través de cambios en el diseño del algoritmo, en lugar de depender únicamente de restricciones durante el entrenamiento. Al reformular el problema y considerar la multiplicidad predictiva, es posible crear modelos que no solo sean precisos, sino también más justos. Este enfoque no solo tiene implicaciones prácticas, como en el caso del IRS, sino también legales, ya que refuerza la necesidad de que las empresas prioricen la justicia en sus sistemas de inteligencia artificial.
En resumen, la justicia en la inteligencia artificial no es solo una cuestión de ajustar parámetros, sino de repensar cómo se diseñan y se seleccionan los modelos para garantizar que sean equitativos y efectivos.
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
Bibliografía
[1] Emily Black, Hadi Elzayn, Alexandra Chouldechova, Jacob Goldin, and Daniel Ho. (2022). Algorithmic Fairness and Vertical Equity: Income Fairness with IRS Tax Audit Models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22). Association for Computing Machinery, New York, NY, USA, 1479–1503. https://doi.org/10.1145/3531146.3533204
[2] Emily Black, Manish Raghavan, and Solon Barocas. (2022). Model Multiplicity: Opportunities, Concerns, and Solutions. In 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22), June 21–24, 2022, Seoul, Republic of Korea. ACM, New York, NY, USA, 23 pages. https://doi.org/10.1145/3531146.3533149
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.