
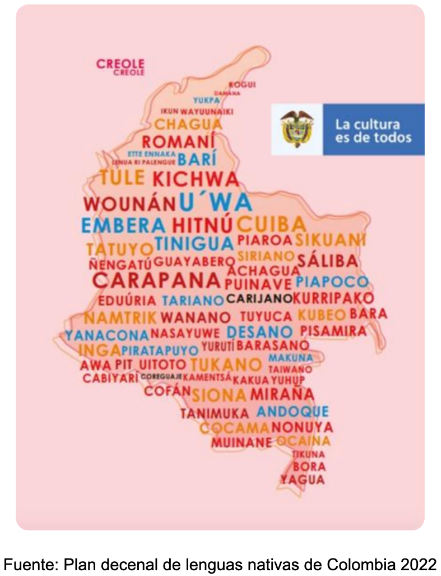
 Según la Organización Nacional Indígena de Colombia (ONIC) existen 69 lenguas habladas en el territorio colombiano, entre las cuales 65 son lenguas indígenas. Esto posiciona a Colombia como el tercer país con mayor diversidad lingüística en el territorio latinoamericano, después de Brasil y México, con una notable concentración en las zonas de la Amazonía y el Vaupés. Además de la diversidad dialectal, existe una riqueza morfológica importante, debido a que en Colombia están representados los cuatro tipos morfológicos clásicos: flexional (Kogui, Arhuaco), aglutinante (Achagua, Andoque, Páez), aislante (Embera, Criollo de San Andrés) y polisintético (Kamsá).
Según la Organización Nacional Indígena de Colombia (ONIC) existen 69 lenguas habladas en el territorio colombiano, entre las cuales 65 son lenguas indígenas. Esto posiciona a Colombia como el tercer país con mayor diversidad lingüística en el territorio latinoamericano, después de Brasil y México, con una notable concentración en las zonas de la Amazonía y el Vaupés. Además de la diversidad dialectal, existe una riqueza morfológica importante, debido a que en Colombia están representados los cuatro tipos morfológicos clásicos: flexional (Kogui, Arhuaco), aglutinante (Achagua, Andoque, Páez), aislante (Embera, Criollo de San Andrés) y polisintético (Kamsá).
Según las Naciones Unidas, al menos el 43% de las aproximadamente 6,000 lenguas habladas en el planeta están en peligro de extinción. Esta situación también se refleja en Colombia, donde muchas lenguas indígenas están en riesgo debido al reducido número de hablantes nativos. La preservación de estas lenguas, que contienen culturas, historias y conocimientos ancestrales, se complica aún más por la preferencia de algunas comunidades por la tradición oral sobre la escrita. Un claro ejemplo es la comunidad Inga, donde se piensa que abandonar las prácticas orales llevaría a la pérdida de otras tradiciones que requieren la interacción y el diálogo entre las personas que fomentan espacios de discusión y cohesión comunitaria.
En 2023, estudiantes y profesores de la Universidad de Los Andes presentaron una propuesta para preservar las lenguas indígenas de Colombia. El proyecto buscaba consolidar conjuntos de datos de traducción de algunas lenguas colombianas, que serían utilizados posteriormente para construir modelos de traducción del español a las lenguas indígenas. Anteriormente, había poca investigación sobre lenguas indígenas en Colombia, con solo dos estudios previos encontrados. Uno de estos estudios se centró en el Wayuunaiki, consolidando un extenso conjunto de datos con pares de frases y palabras traducidas entre ambos idiomas. El otro estudio abarcó tanto el Wayuunaiki como el Nasa, y mostró avances importantes en la consolidación de modelos de traducción. Para el estudio final se tomaron en cuenta las lenguas Wayuunaiki e Ika, dos de las lenguas indígenas más habladas en la actualidad en el territorio.
El Wayuunaiki es una lengua indígena hablada principalmente en la región de La Guajira, en el norte de Colombia, y en partes de Venezuela. Es una lengua aglutinante, lo que significa que las palabras se forman uniendo monemas independientes. En 2018, el censo determinó que la población Wayuu superó los 380,000 habitantes, consolidándose como la comunidad indígena más grande de Colombia. Por otro lado, el Ika es el idioma hablado por la comunidad Arhuaca, que cuenta con más de 34,000 habitantes y se encuentra principalmente en los departamentos de Magdalena, La Guajira y Cesar, con su epicentro en la parte occidental y suroriental de la Sierra Nevada de Santa Marta. Esta lengua pertenece a la familia chibcha y se caracteriza por formar oraciones mediante la adición de varios morfemas a una raíz o lexema.
La consolidación de los datasets para Wayuunaiki e Ika inició con la búsqueda de información, seguida por un procesamiento de las fuentes encontradas. Para Wayuunaiki se utilizaron cuatro fuentes: la biblia, la constitución, un cuento traducido del Wayuu al Español y un diccionario construido por una de las investigaciones previas de traducción de lenguas indígenas que representó la fuente con mayor número de oraciones de todo el proyecto. Para Ika se encontraron de nuevo cuatro fuentes: la biblia, la constitución, un cuento, y una serie de cuentos y poemas. Para ambas lenguas se debieron procesar los datos de distintas formas, utilizando herramientas como web scraping y OCR (optical character recognition) seguido de una revisión manual para la consolidación de los datasets.
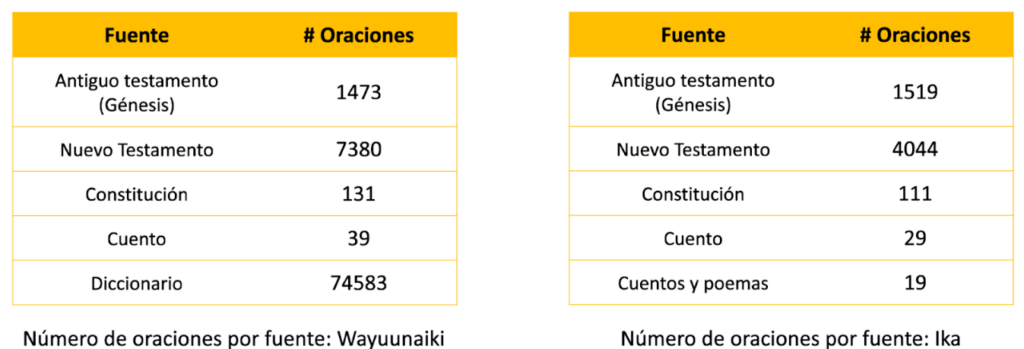
Figura 1: Número de oraciones por fuente de información
Construir un modelo de traducción con una lengua de bajos recursos es una tarea difícil. Los traductores actuales para idiomas como el español, inglés y francés han sido entrenados con cientos de millones de frases traducidas y miles de millones de tokens. Sin embargo, esto no es posible para lenguas de bajos recursos, las cuales se caracterizan por la falta de texto anotado, datos conversacionales y, en general, la ausencia de los recursos necesarios para entrenar modelos de lenguaje efectivos.
Aun así, la existencia de los grandes modelos de lenguaje (LLMs) permite una estrategia diferente al entrenamiento de un modelo de traducción desde cero: es posible utilizar un modelo pre entrenado en lenguas de altos recursos y ajustarlo a los datos de una lengua de bajos recursos utilizando los pocos datos disponibles. Este enfoque se aplicó en dos de las tres estrategias empleadas por Melissa Robles, Cristian Martínez, Juan Camilo Prieto, Sara Palacios y Rubén Manrique. La primera estrategia usó un modelo de traducción de finlandés a español. La segunda utilizó un modelo multilingüe desarrollado por Meta llamado No Language Left Behind (NLLB). La tercera consistió en el entrenamiento de modelos de traducción desde cero, utilizando únicamente los datos recolectados de las dos lenguas indígenas.
La primera estrategia se basó en un modelo previamente entrenado con parejas de frases en español y finlandés de la familia de modelos MarianMT. El finlandés, al igual que muchas lenguas indígenas, es una lengua aglutinante, donde las palabras se forman mediante la unión de morfemas independientes. El segundo modelo, NLLB, fue entrenado con 200 lenguas distintas, incluyendo varias de bajos recursos. Para evitar el sobreajuste de estas, el equipo que desarrolló NLLB implementó técnicas especiales como la regularización, el curriculum learning y el back translation. La última estrategia consistió en el entrenamiento de un modelo de traducción basado en transformers sin ningún entrenamiento previo, utilizando el conjunto de datos que obtuvo los mejores resultados en las dos estrategias anteriores.
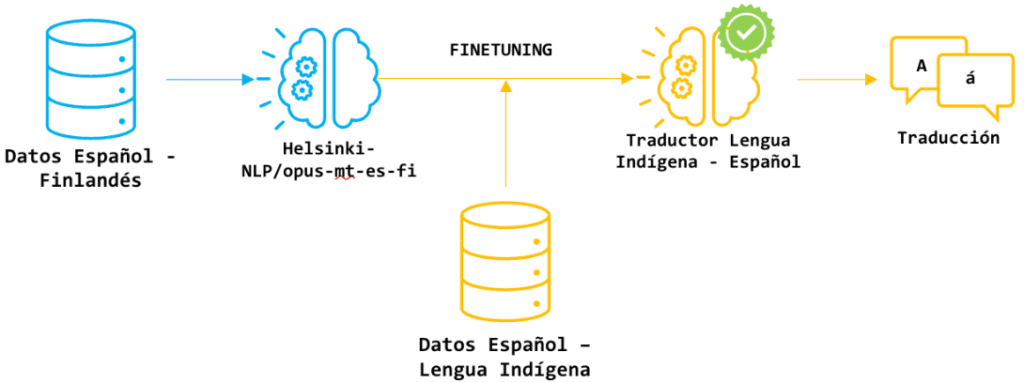
Figura 2: Proceso de ajuste de modelo pre entrenado
Para medir los resultados se utilizaron las métricas BLEU y ChrF++, comúnmente empleadas en tareas de traducción. Los resultados mostraron que las estrategias basadas en modelos previamente entrenados superaron en ambas métricas por más del doble al modelo entrenado únicamente con los datos de las lenguas indígenas, destacando la importancia de utilizar información previa para el entrenamiento. Entre las dos primeras estrategias, la segunda, que emplea el modelo multilingüe, obtuvo los mejores resultados, alcanzando un BLEU superior a 12 puntos y un ChrF++ superior a 35 para Wayuunaiki, y más de 6 y 30, respectivamente, para Ika, utilizando las mejores combinaciones de datos. Para Wayuunaiki, estos resultados superan en más del doble a los obtenidos en estudios anteriores.
Entre los dos modelos base utilizados, el que obtuvo mejores resultados fue el NLLB, debido probablemente a su tamaño y a la inclusión de lenguas de bajos recursos en su entrenamiento. Además, se resalta la importancia de la cantidad y calidad de los datos, evidenciada en la diferencia de métricas entre Wayuunaiki e Ika, atribuida seguramente a la desproporción de recursos digitales entre ambas lenguas. Por ello, se considera que los esfuerzos principales para mejorar los modelos de estas y otras lenguas deben centrarse en la recolección y digitalización de datos, con el objetivo de crear modelos más robustos y actualizados que ayuden a las comunidades a preservar sus tradiciones y lenguas maternas.
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.