El estudio de la justicia algorítmica surge en 2011 con Cynthia Dwork [1], quien se basó en el principio de igualdad de oportunidades: todas las personas, sin importar sus características, deben poder acceder a las mismas oportunidades y beneficios. A partir de ese momento, el estudio de la justicia algorítmica comenzó a ganar popularidad, con el objetivo de identificar y mitigar problemas discriminatorios en los modelos de aprendizaje automático.
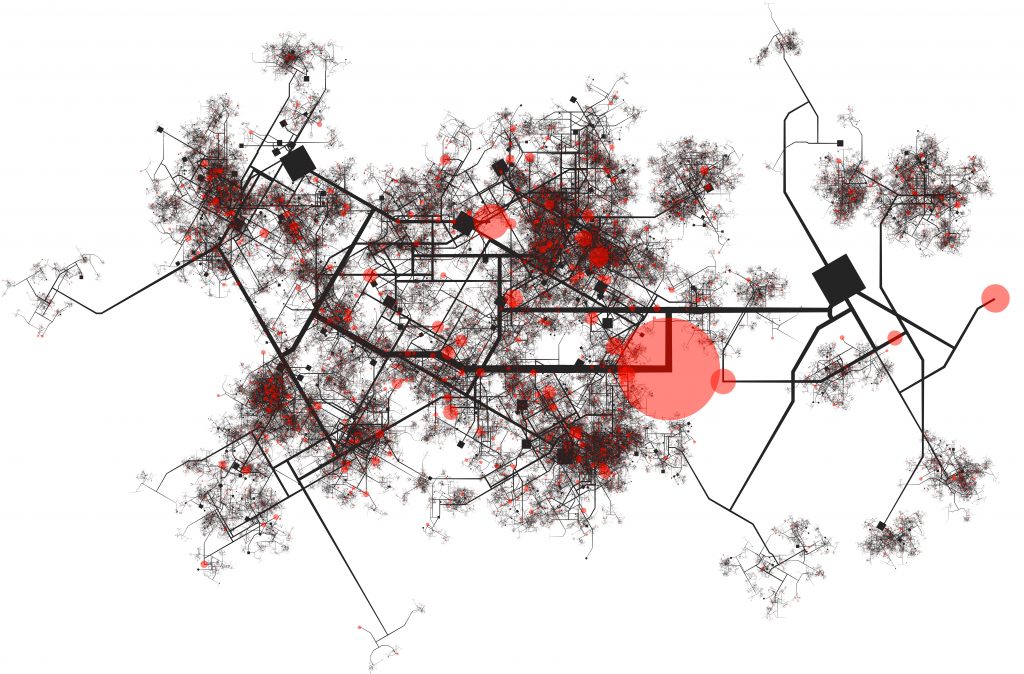
Particularmente preocupantes son los sesgos que pueden estar presentes en los modelos de predicción de crímenes. Los estados que emplean estos modelos confían en las predicciones resultantes para asignar recursos en diferentes áreas de una ciudad. Si el modelo tiene sesgos y, por ejemplo, pronostica más crímenes en zonas de bajos recursos sin que esto se refleje en la realidad, podría perjudicar a los habitantes de esas zonas al imponer una vigilancia innecesaria y excesiva.
Existen diversas causas para los sesgos en los modelos predictivos, siendo tres principales en los modelos de crímenes:
Las métricas comúnmente empleadas para evaluar el desempeño técnico de un modelo no revelan los sesgos subyacentes. Es posible que un modelo tenga una precisión del 98%, cometiendo solo un 2% de errores en sus predicciones. No obstante, si todos esos errores ocurren consistentemente en áreas habitadas por personas de estratos socioeconómicos bajos, podría evidenciarse un sesgo. Por esta razón, siguiendo el trabajo recientemente expuesto por Cristian Pulido, Diego Alejandro Hernández y Francisco Gomez en el seminario de Matemáticas Aplicadas de Quantil, es imperativo definir métricas de evaluación distintas a las tradicionalmente utilizadas. Con este propósito, se establece una función de utilidad ƒ, que puede expresarse de la siguiente manera:
donde el conjunto C abarca todas las áreas protegidas, es decir, zonas que podrían verse afectadas, como las de bajos recursos socioeconómicos. Además, P representa la predicción probabilística, mientras que Q representa los crímenes simulados. En términos intuitivos, el objetivo es minimizar la disparidad entre estas dos distribuciones, logrando un modelo que capture la estructura subyacente de las distribuciones de crímenes.
A partir de este valor, se calculan algunas métricas de justicia como la varianza, la diferencia min-max y el valor Gini. Resulta particularmente importante analizar la relación entre estas métricas de justicia y las métricas tradicionales de rendimiento técnico. Este es el objetivo de Cristian Alejandro Pulido, y Diego Alejandro Hernández bajo la dirección de Francisco Gomez [2]. Para este fin, se simularon 30 escenarios siguiendo la distribución usual de población en ciudades latinoamericanas, las cuales se distribuyen como un Sector Model:
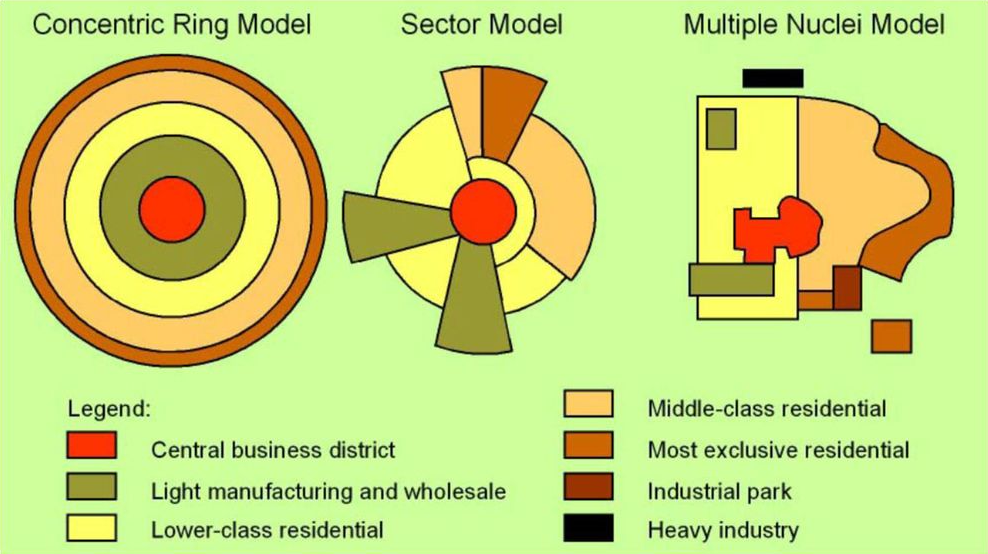
A partir de estas simulaciones se entrenaron tres modelos comúnmente utilizados en este ámbito: NAIVE, KDE y SEPP. Para cada uno de estos se analizó su rendimiento técnico comparando la distribución real simulada de la predicha por medio de la earth mover’s distance, y sus posibles sesgos a partir de la varianza, distancia max-min y Gini de la función de utilidad.
De estos experimentos se puede evidenciar que hay una tendencia de los modelos mejor ajustados a tener mayores injusticias, lo cual puede ser un problema social dado que la elección de un modelo comúnmente se basa únicamente en este tipo de métricas tradicionales. Al ignorar las métricas de justicia se puede estar incurriendo en sesgos implícitos y perjudicando a poblaciones históricamente discriminadas.
Aunque en las simulaciones se siguió una distribución poblacional usual en latinoamérica, los datos artificiales no siempre representan la realidad. En particular no cuentan con las problemáticas de desbalance y ausencia de datos. Es por esto que la investigación continuará para evidenciar qué impactos se tienen sobre datos reales de crímenes, y adicionalmente para analizar cómo el subreporte puede impactar la justicia de los modelos.
Referencias
[1] Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold y Richard Zemel. Fairness Through Awareness, 2011.
[2] Cristian Pulido, Diego Alejandro Hernández y Francisco Gomez. Análisis sobre la justicia de los modelos más usuales en Seguridad Predictiva. https://www.youtube.com/watch?v=uCIanZ8jT-4
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.