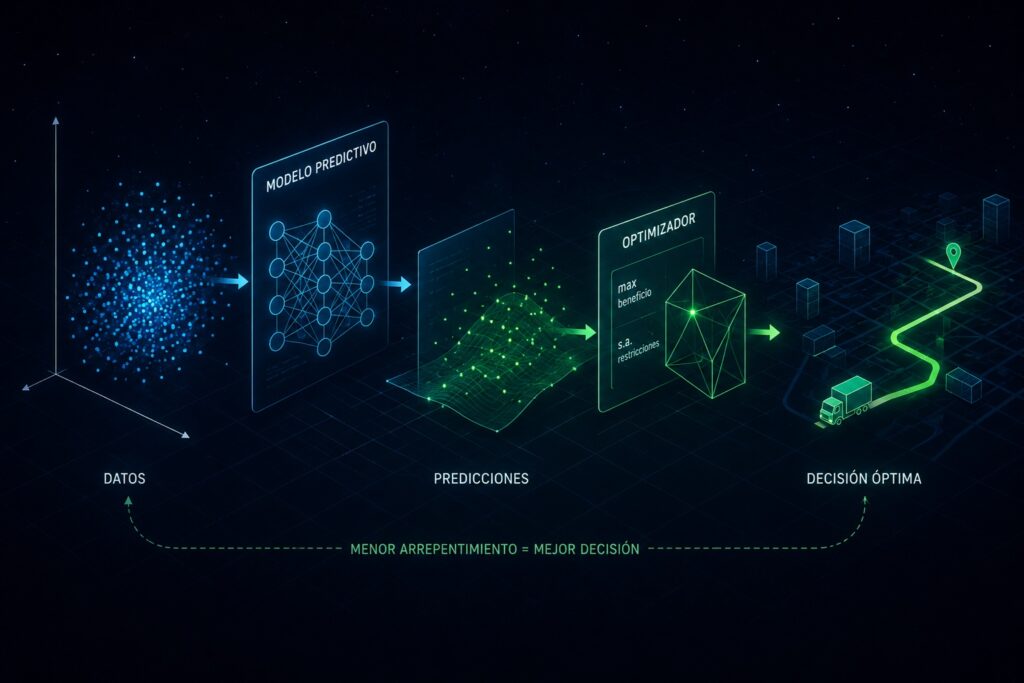
The standard way to evaluate predictive models is dominated by a simple idea: if prediction error decreases, the model is better. Metrics such as MSE or accuracy have become the standard in most industrial pipelines. However, there is a broad class of problems where this logic fails: situations in which a prediction is not used merely to estimate something, but to make decisions.
The typical case is a predict-then-optimize: a model predicts a variable of interest, and then an optimizer uses that prediction to decide what to do. For example, estimating future demand to decide how much inventory to order, or predicting costs to determine logistics routes. In these scenarios, minimizing prediction error does not always imply making better decisions.
Paula Rodríguez-Díaz, a doctoral student at Harvard, presented on April 17 at Quantil’s Applied Mathematics seminar a paper published in UAI 2025 that addresses precisely this problem. The central question of the talk was: when does being wrong in a prediction really matter?
The classic assumption is intuitive: if a model produces more accurate predictions, then the resulting decisions should also improve. But this is not always the case.
Imagine a truck-loading system. A large error in the price of a small product may not alter the loading plan at all. In contrast, a tiny error in a bulky product could completely change the selection of goods and significantly affect profits. MSE treats both errors as comparable, even though their operational impact is very different.
This difference between optimizing prediction and optimizing decisions is known as misalignment, and it is the starting point of the approach known as decision-focused learning.
The literature proposes replacing purely predictive metrics with a decision-centered measure: decision regret o arrepentimiento.
The idea is to compare two scenarios: the first, where the optimizer knows the true values and makes the best possible decision; the second, where only predictions are available and decisions must be made with imperfect information. Regret measures how much worse the decision made using predictions is compared to the ideal decision.
The important consequence is that a model can make substantial errors in regions where the final decision does not change and still perform well. Conversely, small errors near “decision boundaries” can become extremely costly. Training models by minimizing regret forces the system to focus accuracy precisely where the decision is sensitive.
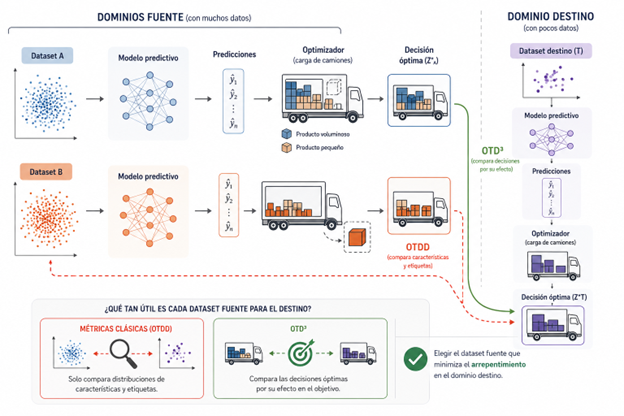
The main contribution of the work by Rodríguez-Díaz and her coauthors emerges when the problem is extended to transfer learning.
In practice, it is common to have little data from the target domain and several related datasets available for pretraining. The challenge is deciding which of these datasets is truly useful. The usual answer is to choose the one “most similar” to the target domain, but this raises a key question: similar in what sense?
Classical metrics, such as OTDD (Optimal Transport Dataset Distance), compare datasets using similarity between features and labels. The problem is that these metrics completely ignore the decisions resulting from those data.
Two datasets may look statistically very different and still induce exactly the same optimal plan. The opposite can also happen: seemingly similar datasets may produce radically different decisions if the optimizer is sensitive to certain regions of the space.
The proposal introduced in the paper is called OTD³ (Optimal Transport Decision-aware Dataset Distance). The core idea is to extend optimal transport to compare not only features and labels, but also the optimal decisions associated with each problem.
Instead of measuring only statistical similarity, OTD³ incorporates the effect that differences between datasets have on the final optimization objective. Two decisions may look geometrically different and still be operationally equivalent if they produce the same cost or benefit. OTD³ compares precisely that functional impact.
The authors also show that this distance makes it possible to formally bound the expected regret in the target domain: if a source dataset is close to the target according to OTD³, then transfer learning should preserve good decision-making performance.
One of the most interesting results of the paper has to do with so-called target shift: situations in which label distributions change across domains.
In traditional supervised learning, this is usually interpreted as a serious transfer problem. But in the context predict-then-optimize, the paper shows that some changes in labels do not actually affect performance if the optimal decisions remain the same.
In other words, what matters is not only whether the data change, but whether those changes modify the actions the system takes. It is a simple observation, but one with deep consequences for the evaluation of applied models.
For developers, implementing this poses a technical challenge: how do we perform backpropagation through a mathematical optimizer that is not differentiable? The community is addressing this in two ways: by rewriting optimizers so they allow gradients to pass through, or by designing surrogate loss functions that approximate regret.
For those working in logistics optimization, operational planning, or decision systems, the message is direct: improving predictive metrics does not guarantee better business outcomes.
The work by Rodríguez-Díaz proposes a different way of thinking about machine learning: evaluating models not only by how well they predict, but by how good the decisions they produce are.
Even without completely redesigning a pipeline, OTD³ offers a useful tool for selecting pretraining datasets, evaluating transfer across domains, and determining when data from other regions or contexts truly add value.
Reference:
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.