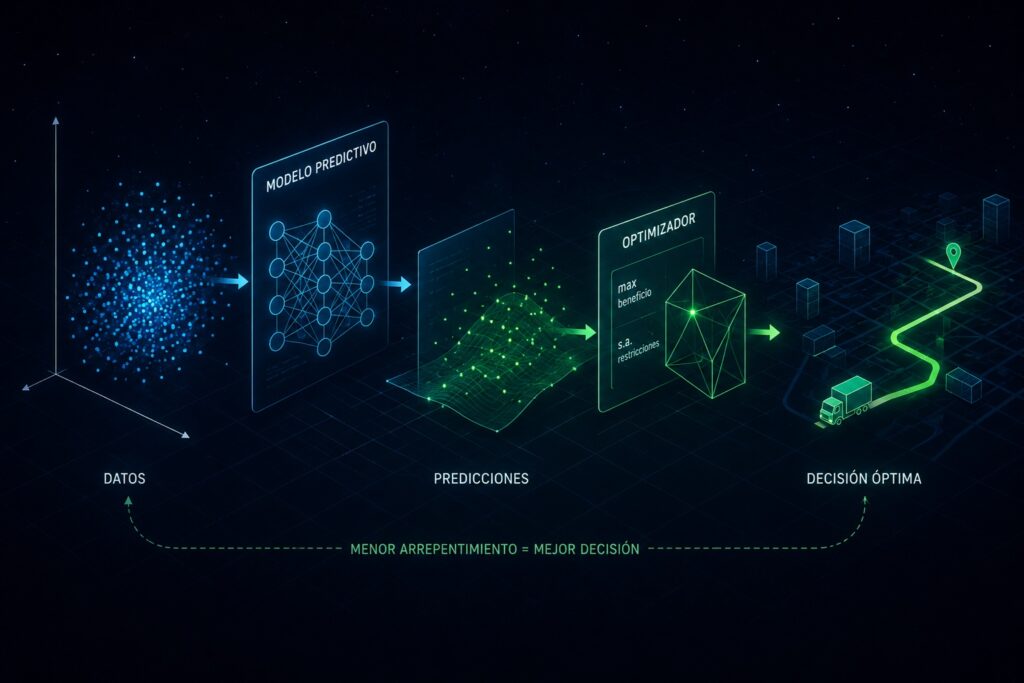
La forma estándar de evaluar modelos predictivos es dominada por una idea simple: si baja el error de predicción, el modelo es mejor. Métricas como el MSE o el accuracy se han convertido en el estándar en la mayoría de pipelines industriales. Sin embargo, existe una clase amplia de problemas donde esta lógica falla: situaciones en las que una predicción no se usa solo para estimar algo, sino para tomar decisiones.
El caso típico es un flujo predict-then-optimize: un modelo predice una variable de interés y luego un optimizador usa esa predicción para decidir qué hacer. Por ejemplo, estimar demanda futura para decidir cuánto inventario pedir, o predecir costos para definir rutas logísticas. En estos escenarios, minimizar el error predictivo no siempre implica tomar mejores decisiones.
Paula Rodríguez-Díaz, estudiante doctoral en Harvard, presentó este 17 de abril en el seminario de Matemáticas Aplicadas de Quantil un trabajo publicado en UAI 2025 que aborda precisamente este problema. La pregunta central de la charla fue: ¿cuándo equivocarse en una predicción realmente importa?
El supuesto clásico es intuitivo: si un modelo produce predicciones más precisas, entonces las decisiones derivadas también deberían mejorar. Pero no siempre es así.
Imagine un sistema de carga de camiones. Un error grande en el precio de un producto pequeño puede no alterar en absoluto el plan de carga. En cambio, un error mínimo en un producto voluminoso podría cambiar completamente la selección de mercancía y afectar significativamente las ganancias. El MSE trata ambos errores como comparables, aunque su impacto operativo sea muy distinto.
Esta diferencia entre optimizar predicción y optimizar decisiones se conoce como desalineación, y es el punto de partida del enfoque conocido como decision-focused learning.
La literatura propone reemplazar las métricas puramente predictivas por una medida centrada en decisiones: el decision regret o arrepentimiento.
La idea es comparar dos escenarios: el primero, donde el optimizador conoce los valores reales y toma la mejor decisión posible; el segundo, donde solamente se dispone de predicciones y se debe decidir con información imperfecta. El arrepentimiento mide cuánto empeora la decisión tomada usando predicciones respecto a la decisión ideal.
La consecuencia importante es que un modelo puede equivocarse bastante en regiones donde la decisión final no cambia, y aún así funcionar bien. Por el contrario, pequeños errores cerca de “fronteras de decisión” pueden resultar extremadamente costosos. Entrenar modelos minimizando arrepentimiento fuerza al sistema a concentrar precisión precisamente donde la decisión es sensible.
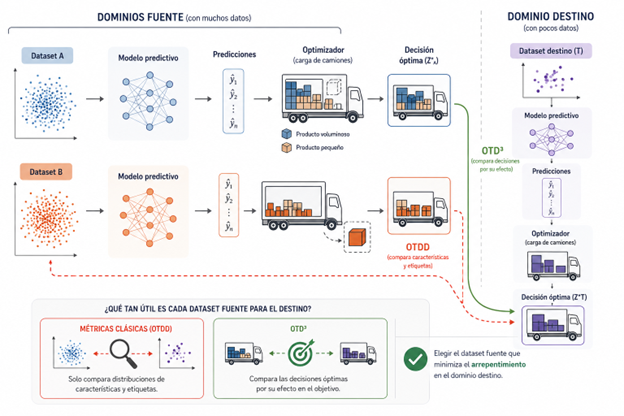
El aporte principal del trabajo de Rodríguez-Díaz y sus coautores aparece cuando el problema se traslada al aprendizaje por transferencia.
En la práctica es común tener pocos datos del dominio objetivo y varios datasets relacionados disponibles para preentrenamiento. El problema es decidir cuál de estos datasets es realmente útil. La respuesta habitual consiste en elegir el “más parecido” al dominio destino, pero surge una pregunta clave: ¿parecido en qué sentido?
Las métricas clásicas, como OTDD (Optimal Transport Dataset Distance), comparan datasets usando similitud entre features y etiquetas. El problema es que estas métricas ignoran completamente las decisiones que resultan de esos datos.
Dos datasets pueden verse muy distintos estadísticamente y, aun así, inducir exactamente el mismo plan óptimo. También puede ocurrir lo contrario: datasets aparentemente similares pueden producir decisiones radicalmente diferentes si el optimizador es sensible a ciertas regiones del espacio.
La propuesta del artículo se llama OTD³ (Optimal Transport Decision-aware Dataset Distance). La idea central es extender el transporte óptimo para comparar no solo características y etiquetas, sino también las decisiones óptimas asociadas a cada problema.
En lugar de medir únicamente similitud estadística, OTD³ incorpora el efecto que las diferencias entre datasets tienen sobre el objetivo final de optimización. Dos decisiones pueden verse geométricamente distintas y aun así ser equivalentes desde el punto de vista operativo si producen el mismo costo o beneficio. OTD³ compara precisamente ese impacto funcional.
Los autores muestran además que esta distancia permite acotar formalmente el arrepentimiento esperado en el dominio destino: si un dataset fuente está cerca del objetivo según OTD³, entonces la transferencia debería mantener buen desempeño decisional.
Uno de los resultados más interesantes del trabajo tiene que ver con el llamado target shift: situaciones donde cambian las distribuciones de etiquetas entre dominios.
En aprendizaje supervisado tradicional, esto suele interpretarse como un problema serio de transferencia. Pero en el contexto predict-then-optimize, el artículo muestra que algunos cambios en etiquetas no afectan realmente el desempeño si las decisiones óptimas permanecen iguales.
En otras palabras, lo importante no es únicamente si los datos cambian, sino si estos cambios modifican las acciones que el sistema toma. Es una observación simple, pero con consecuencias profundas para la evaluación de modelos aplicados.
Para los desarrolladores, implementar esto supone un reto técnico: ¿cómo hacemos backpropagation a través de un optimizador matemático que no es diferenciable? La comunidad lo está resolviendo de dos formas: reescribiendo los optimizadores para que permitan el paso de gradientes, o diseñando funciones de pérdida sustitutas (surrogate losses) que aproximen el arrepentimiento.
Para quienes trabajan en optimización logística, planeación operativa o sistemas de decisión, el mensaje es directo: mejorar métricas predictivas no garantiza mejorar resultados de negocio.
El trabajo de Rodríguez-Díaz propone una manera distinta de pensar el aprendizaje automático: evaluar modelos no solo por qué tan bien predicen, sino por qué tan buenas son las decisiones que producen.
Incluso sin rediseñar completamente un pipeline, OTD³ ofrece una herramienta útil para elegir datasets de preentrenamiento, evaluar transferencia entre dominios y determinar cuándo datos de otras regiones o contextos realmente aportan valor.
Referencia:
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.