
The internal armed conflict in Colombia represents a large portion of the country's history. The dispute for power and territorial control between different armed groups and state institutions has unleashed the violation of human rights, mainly against the civilian population, which is always in the middle of the conflict. In the framework of the Final Agreement for the Termination of the Conflict and the Construction of a Stable and Lasting Peace, signed in 2016, the Commission for the Clarification of Truth, Coexistence, and Non-Repetition (Truth Commission) was created in 2017, as a mechanism to know the truth of what happened in the framework of the armed conflict and contribute to the clarification of the violations and infractions committed during the conflict (Truth Commission, 2017). Likewise, the Commission seeks to provide inputs for the construction of the state policy on victims.
The Truth Commission works hand in hand with the Special Jurisdiction for Peace (JEP), which represents the justice component of the Comprehensive System of Truth, Justice, Reparation, and Non-Repetition within the framework of the Final Agreement. The joint work of these two organizations, together with the support of the Human Right Data Analysis Group (HRDAG), resulted in the Final Report of the Truth Commission, which had among its objectives to show the findings related to the Armed Conflict in Colombia. The construction of this report had an enormous challenge: the estimation of the underreporting of victims of the conflict. María Juliana Durán and Paula Andrea Amado, HRDAG consultants, explain the methodology developed to face this challenge.
(See seminar Truth Commission data: estimation of the underreporting of victims)
The conflict in Colombia has been extensively documented by entities with different methodologies and scopes. HRDAG made use of 112 databases from 44 different sources that constituted a base of nearly 13 million records. The objectives of the project were focused on making a statistical analysis of patterns of violence in the period 1985-2018, eliminating duplicate data from the 112 databases used, imputing missing fields in the records, and estimating underreporting. All of the above are for four types of human rights violations: homicide, kidnapping, recruitment, and disappearance. As an example, Figure 1 shows the number of victims by the perpetrator, according to the Single Registry of Victims (RUV) and the National Center of Historical Memory (CNMH).
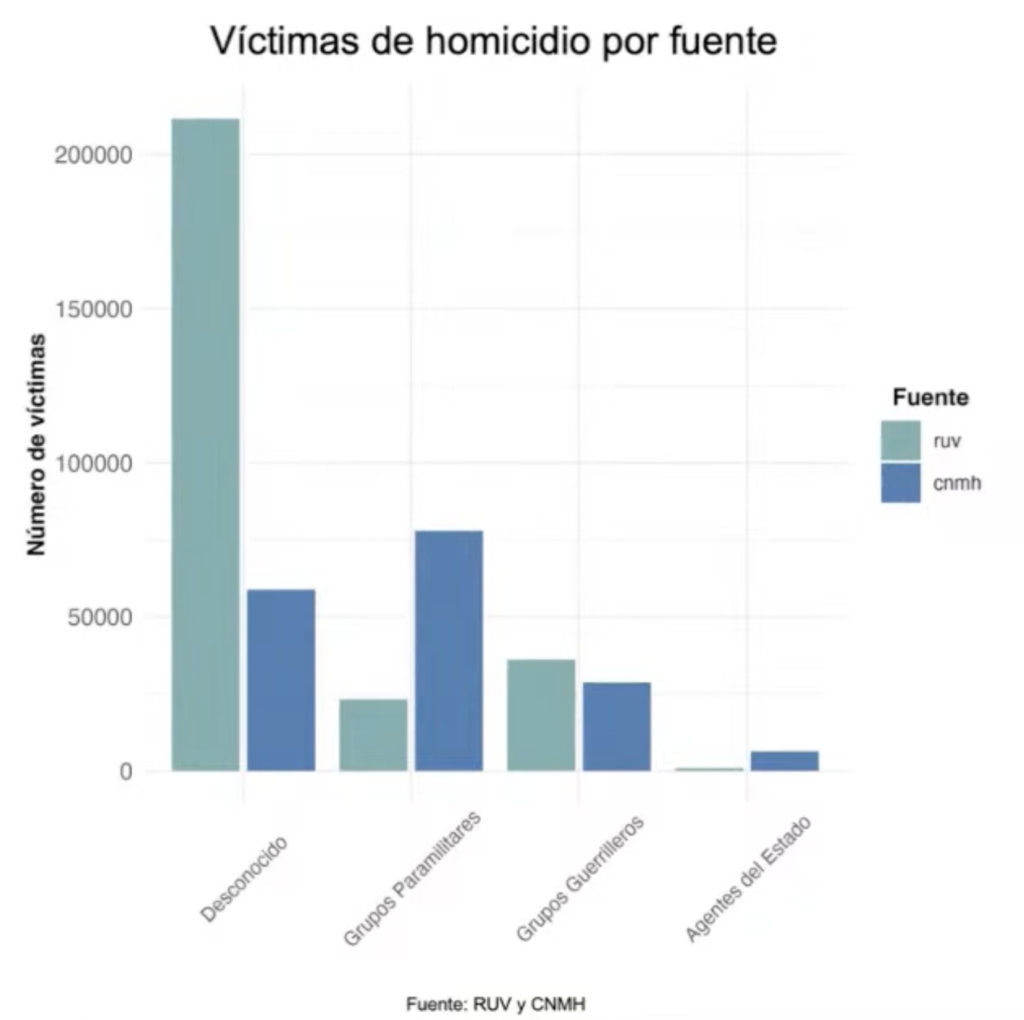
Figure 1. Comparison of RUV and CNMH homicide records, by perpetrator. Prepared by HRDAG.
To achieve these objectives, the project was divided into three stages.
To identify multiple records that possibly belong to the same victim, three categories of models have been defined:
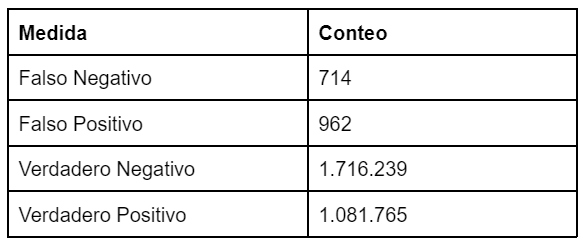
Figure 2. Results of testing the cluster model in the identification of duplicate records. Prepared by HRDAG.
At the end of this process it was concluded that, of the almost 13 million initial records, 8,775,884 are unique records.
The probability of a victim being registered in several databases depends, for example, on the city in which he or she resides and whether or not he or she is a public figure. Eliminating these duplicate records is essential so that the data accurately reflect the dynamics of the conflict and do not over-represent certain groups.
1 In this context, an "oracle" is a person or tool that, like Michelle, is responsible for assigning labels of a particular category to each observation in a database.
The database of unique records generated in the previous stage contains characteristics (fields) of each documented violent event. For example, an organization to which the perpetrator belonged; gender, age, and ethnicity of the victim; date and location of the event, etc... With such a large number of records, missing fields are not a problem per se. If a missing field were random, this would not have a major impact on the analysis. However, the fact that a field is missing is related to variables such as the date of the event (because the victim registration system has changed over time) or the location (because there is a disparity in the reporting capabilities of each region).
Taking these observed variables into account corrects for bias. The researchers hypothesize that the missing values of a variable follow a pattern similar to the observed values, conditional on the other observed variables. Thus, they make use of the MAR: Missing at Random, which consists of constructing chained equations with a specification conditional on the observed data, containing information on how the variables are related —for example, the gender and age of the victim— and a random component. This equation is used to impute missing data, when available, to each record. The process is repeated multiple times to estimate the parameters of interest for each data set, and finally, the estimates are combined to generate a point prediction for the missing data, applying Rubin's combination rules. This methodology was implemented using the Predictive mean matching of the R mice package.
The different databases contain heterogeneous information, so they are divided into base variables (those that may have missing information and are relevant to the study) and support variables. The latter are constructed using additional information from the databases. For example, the murder weapon, the sidewalk or location, the victim's profession, or the account of the event. It is precisely the account of the event, after being cleaned and lemmatized, that is used for the construction of a neural network of the Long-Short Term Memory (LSTM) type that allows estimating the probability score of a supporting variable for each category of a violent event (i.e. that it was a homicide, that it was committed by guerrilla groups, etc.).
Again, underreporting (events that are not recorded in any database) does not exist by chance, but because of structural differences in the armed conflict scenario: absence of entities to record complaints, fear of reporting due to possible threats, geographical difficulties, among others. Also, there are ethnic, geographic, or ideological groups that are systematically less likely to be registered when they experience a human rights violation.
Given the above, the researchers employed Multiple Systems Estimation (MSE) to adequately address the problem of underreporting of victims. MSE is applicable when four assumptions are met:
This approach seeks to approximate the real size of a population (number of victims of each human rights violation) based on the patterns of documentation of the events: if an event is documented multiple times by several sources2 and the above assumptions are met, the size of the underreporting is not so significant. On the other hand, if the coincidences between databases are small, the underreporting is estimated to be larger.
By applying this method, a confidence interval can be estimated for the actual number of victims for each year between 1985 and 2018. Figure 3 shows the result for the case of enforced disappearance. It is concluded, among others, that the increase in this phenomenon in the early 2000s was more pronounced than previously believed and that in 2007 there was a peak in underreporting.
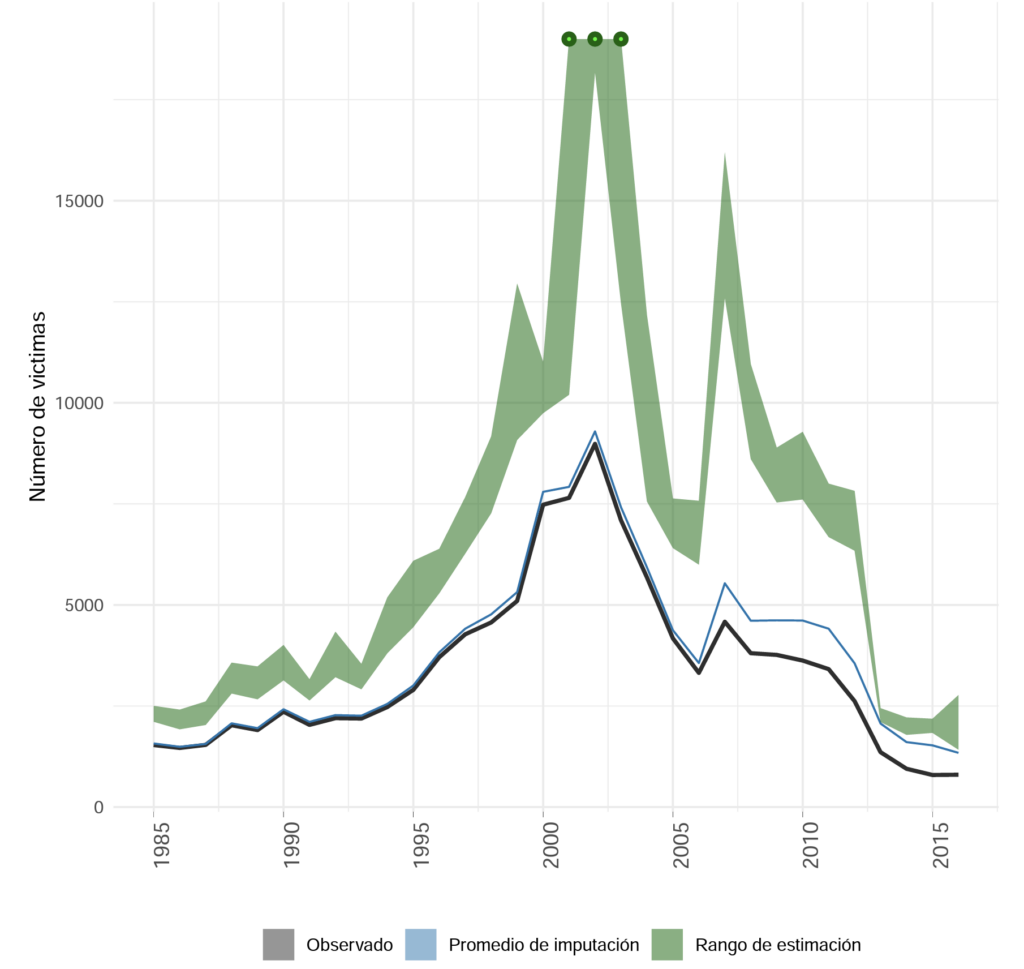
Figure 3. Victims of enforced disappearance between 1985 and 2016. Taken from the Methodological Report of the joint JEP-CEV-HRDAG data integration and statistical estimation project (2022).
2 In the case of forced disappearance, most records are provided by the RUV, which compromises the robustness of the methodology according to the National Administrative Department of Statistics (Dane, 2023).
Some implications
The results of this analysis are relevant on two fronts: on the one hand, having more precise records on human rights violations allows for better quantitative analysis of these phenomena and more accurate formulation of public policy on victims; on the other hand, underreporting is in itself an interesting variable to study. These data indicate which periods, places, and population groups have had the worst monitoring of human rights violations during the armed conflict and, thus, indicate how well state and non-state capacities have been used to document these phenomena. In sum, this research generates a great contribution to clarifying the magnitude and characteristics of the violence generated by such a complex phenomenon as the Colombian armed conflict.
The results of the estimates for the different human rights violations are published by the National Administrative Department of Statistics (DANE, 2023). They can be accessed through this link. The final database, constructed with the methodology described here, is organized temporally and geographically, which will allow the development of future research on the dynamics of the conflict and its relationship with other institutional, social, and economic variables.
Sources
Links of interest
Get information about Data Science, Artificial Intelligence, Machine Learning and more.
In the Blog articles, you will find the latest news, publications, studies and articles of current interest.