
El conflicto armado interno en Colombia representa una gran porción en la historia del país. La disputa por poder y control territorial entre los distintos grupos armados y las instituciones estatales ha desatado la violación de derechos humanos, principalmente en contra de la población civil, que siempre queda en medio del conflicto. En el marco del Acuerdo Final para la Terminación del Conflicto y la Construcción de una Paz Estable y Duradera, suscrito en el año 2016, se creó en 2017 la Comisión para el Esclarecimiento de la Verdad, la Convivencia y la No Repetición (Comisión de la Verdad), como un mecanismo para conocer la verdad de lo ocurrido en el marco del conflicto armado y contribuir al esclarecimiento de las violaciones e infracciones cometidas durante el mismo (Comisión de la Verdad, 2017). Así mismo, la Comisión busca aportar insumos para la construcción de la política estatal de víctimas.
La Comisión de la Verdad trabaja de la mano de la Jurisdicción Especial para la Paz (JEP), que representa al componente de justicia del Sistema Integral de Verdad, Justicia, Reparación y no Repetición en el marco del Acuerdo Final. El trabajo mancomunado de estas dos organizaciones, junto con el apoyo del Human Right Data Analysis Group (HRDAG), dio como resultado el Informe Final de la Comisión de la Verdad, que tuvo entre sus objetivos mostrar los hallazgos relacionados con el Conflicto Armado en Colombia. La construcción de este informe tuvo un reto enorme: la estimación del subregistro de víctimas del conflicto. María Juliana Durán y Paula Andrea Amado, consultoras del HRDAG, nos explican la metodología desarrollada para enfrentar este reto.
(Ver seminario Datos de la Comisión de la Verdad: estimación del subregistro de víctimas)
El conflicto en Colombia ha sido ampliamente documentado por entidades que tienen distintas metodologías y alcances. El HRDAG hizo uso de 112 bases de datos provenientes de 44 fuentes diferentes que constituían una base de cerca de 13 millones de registros. Los objetivos del proyecto estuvieron enfocados en hacer un análisis estadístico de patrones de los violencia en el periodo 1985-2018, eliminar los datos duplicados de las 112 bases usadas, imputar los campos faltantes en los registros y estimar el subregistro. Todo lo anterior, para cuatro tipos de violaciones a derechos humanos: homicidio, secuestro, reclutamiento y desaparición. Como ejemplo, la Figura 1 exhibe el número de víctimas según responsable, de acuerdo al Registro único de Víctimas (RUV) y al Centro Nacional de Memoria Histórica (CNMH).
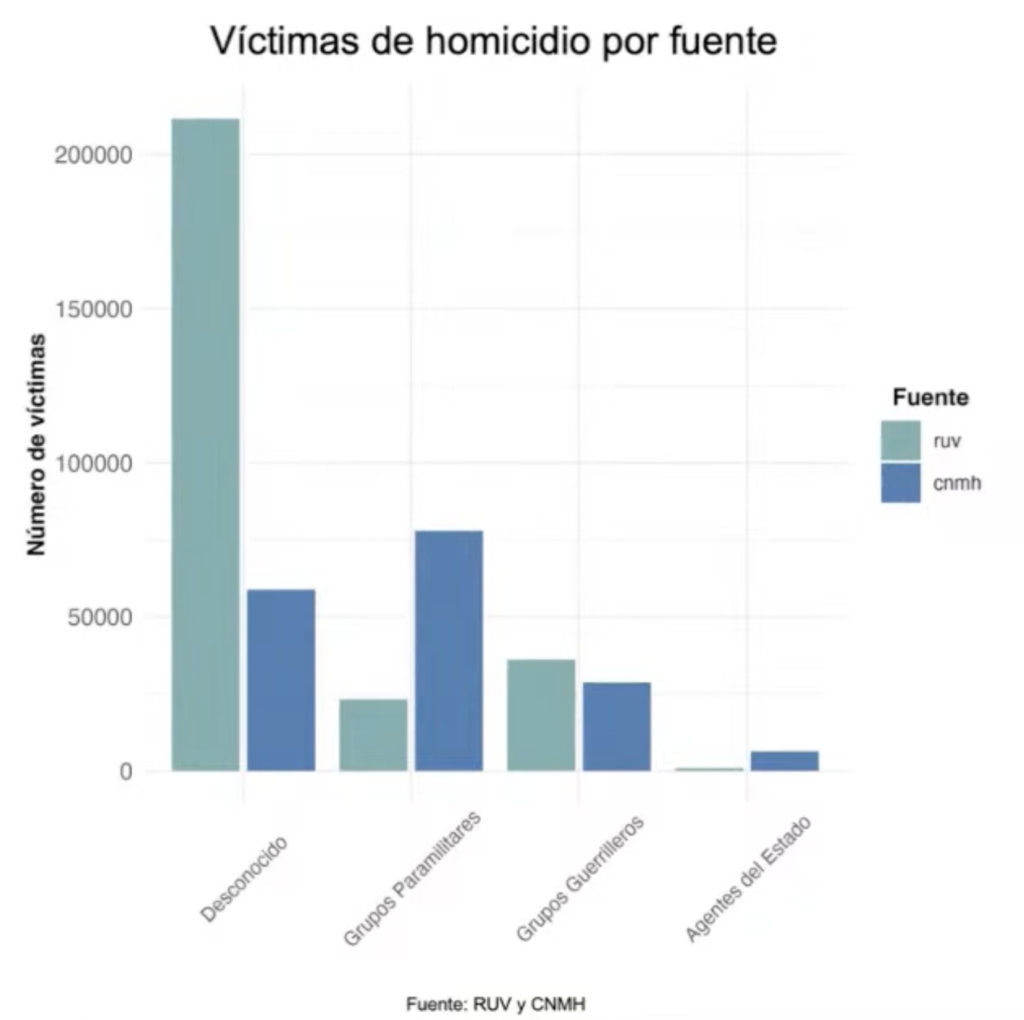
Figura 1. Comparación de registros de homicidios del RUV y del CNMH, por responsable. Elaborado por HRDAG.
Para lograr estos objetivos, el proyecto se dividió en tres etapas.
Para hacer la identificación de múltiples registros que, posiblemente, pertenecen a la misma víctima se definieron tres categorías de modelos:
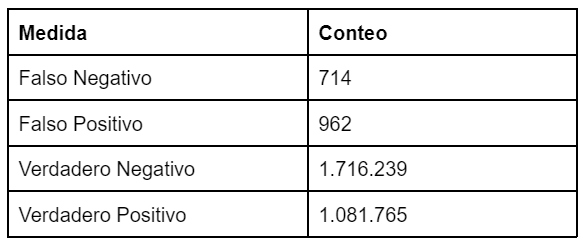
Figura 2. Resultados de testeo del modelo de grupos en la identificación de registros duplicados. Elaborado por HRDAG.
Al finalizar este proceso se concluyó que, de los casi 13 millones de registros iniciales, 8.775.884 son registros únicos.
La probabilidad de que una víctima sea registrada en varias bases de datos depende, por ejemplo, de la ciudad en la que reside y de si es o no una figura pública. Eliminar estos registros duplicados es esencial para que los datos reflejen fielmente las dinámicas del conflicto y no sobre representen a ciertos grupos.
1 En este contexto, se conoce como “oráculo” a una persona o herramienta que, como Michelle, se encarga de hacer la asignación de etiquetas de una categoría en particular a cada observación de una base de datos.
La base de registros únicos generada en la etapa anterior contiene características (campos) de cada hecho violento documentado. Por ejemplo, organización a la que pertenecía el perpetrador, género, edad y etnia de la víctima; fecha y ubicación del hecho, etc… Con una cantidad tan grande de registros, los campos faltantes no son un problema per se. Si el hecho de que un campo falte fuera aleatorio, esto no tendría mayor impacto en el análisis. Sin embargo, el hecho de que un campo falte está relacionado con variables como la fecha del hecho (porque el sistema de registro de víctimas ha cambiado a lo largo del tiempo) o la ubicación (porque hay disparidad en las capacidades de reporte de cada región).
Al tener en cuenta esta variables observadas se corrige el sesgo. Los investigadores hacen la hipótesis de que los valores faltantes de una variable siguen un patrón similar a los valores observados, condicionados al resto de variables observadas. Así, hacen uso de la metodología MAR: Missing at Random, que consiste en construir ecuaciones encadenadas con una especificación condicionada a los datos observados, que contengan información sobre cómo se relacionan las variables —por ejemplo, el género y la edad de la víctima— y un componente aleatorio. Esta ecuación sirve para imputar los datos faltantes, cuando los haya, a cada registro. El proceso se repite múltiples veces para estimar los parámetros de interés de cada conjunto de datos, y finalmente se combinan las estimaciones para generar una predicción puntual de los datos faltantes, aplicando las reglas de combinación de Rubin. Esta metodología se implementó mediante el método Predictive mean matching del paquete mice de R.
Las diferentes bases de datos contienen información heterogénea, por lo que esta se divide entre variables de base (aquellas que pueden presentar información faltante y que son relevantes en el estudio) y variables de soporte. Estas últimas se construyen mediante información adicional de las bases de datos. Por ejemplo, el arma homicida, la vereda o ubicación, la profesión de la víctima o el relato del hecho. Justamente el relato de hecho, luego de ser limpiado y lematizado, se usa para la construcción de una red neuronal del tipo Long-Short Term Memory (LSTM) que permite estimar el score de probabilidad de una variable de soporte para cada categoría de un evento violento (i.e que haya sido homicidio, que haya sido cometido por grupos guerrilleros, etc.).
Nuevamente, el subreporte (hechos que no se registran en ninguna base de datos) no existe por azar, sino por diferencias estructurales en el escenario del conflicto armado: ausencia de entidades que registren las denuncias, el miedo a denunciar por posibles amenazas, dificultades geográficas, entre otras. También, hay grupos étnicos, geográficos o ideológicos que sistemáticamente tiene menor probabilidad de ser registrados cuando experimentan una violación a los derechos humanos.
Dado lo anterior, los investigadores emplearon la Estimación por Sistemas Múltiples (ESM) para abordar adecuadamente el problema del subreporte de víctimas. La ESM es aplicable cuando se cumplen cuatro supuestos:
Este enfoque busca aproximar el tamaño real de una población (número de víctimas de cada violación a derechos humanos) a partir de los patrones de documentación de los hechos: si un hecho es documentado múltiples veces por varias fuentes2 y se cumplen los anteriores supuestos, el tamaño del subregistro no es tan significativo. En cambio, si las coincidencias entre bases de datos son reducidas, se estima que el subregistro es mayor.
Al aplicar este método, se puede estimar un intervalo de confianza para el número real de víctimas de cada año entre 1985 y 2018. La figura 3 muestra el resultado para el caso de desaparición forzada. Se concluye, entre otros, que el aumento de este fenómeno a comienzos de los 2000 fue más pronunciado que lo que se creía y que en 2007 hubo un pico de subregistros.
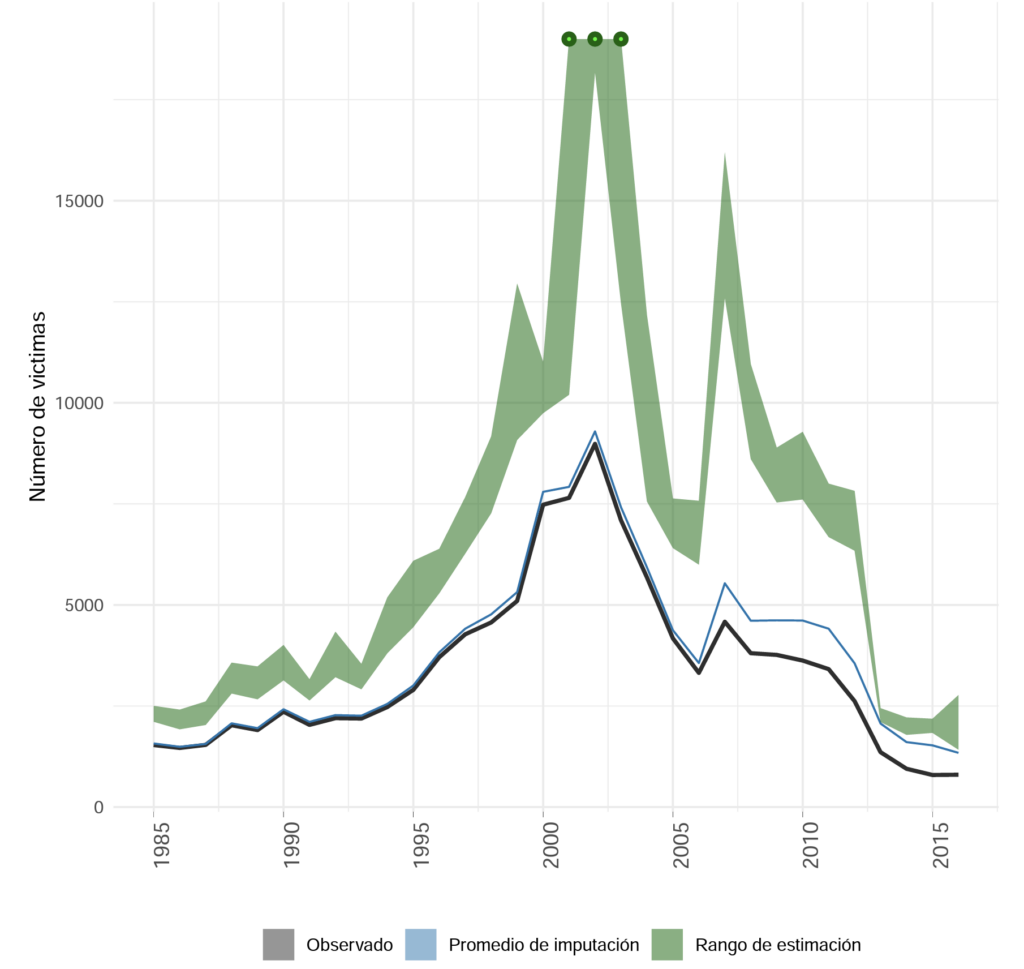
Figura 3. Víctimas de desaparición forzada entre 1985 y 2016. Tomado del Informe metodológico del proyecto conjunto JEP-CEV-HRDAG de integración de datos y estimación estadística (2022).
2 En el caso de la desaparición forzada, la mayoría de registros son aportados por el RUV, lo que compromete la robustez de la metodología según el Departamento Administrativo Nacional de Estadística (Dane, 2023)
Algunas implicaciones
Los resultados de este análisis son relevantes en dos frentes: por un lado, contar con registros más precisos sobre violaciones a los derechos humanos permite mejorar los análisis cuantitativos que se hagan sobre estos fenómenos y formular con mayor exactitud la política pública de víctimas; por otro lado, el subregistro es en sí mismo una variable interesante para estudiar. Estos datos indican qué periodos, lugares y grupos poblacionales han tenido peor monitoreo de violaciones a derechos humanos durante el conflicto armado y, con ello, indican qué tan bien se han empleado las capacidades estatales y no estatales para documentar estos fenómenos. En suma, esta investigación genera un gran aporte para esclarecer la magnitud y características de la violencia generada por un fenómeno tan complejo como el conflicto armado colombiano.
Los resultados de las estimaciones para las distintas violaciones de derechos humanos se encuentran publicados por el Departamento Administrativo Nacional de Estadística (DANE, 2023). Se puede acceder a ellos a través de este enlace. La base de datos final, construida con la metodología aquí descrita, está organizada temporal y geográficamente, lo que permitirá desarrollar futuras investigaciones sobre la dinámica del conflicto y su relación con otras variables institucionales, sociales y económicas.
Fuentes
Links de interés
Obtén información sobre Ciencia de datos, Inteligencia Artificial, Machine Learning y más.
En los artículos de Blog, podrás conocer las últimas noticias, publicaciones, estudios y artículos de interés de la actualidad.